

微软研究院刚刚推出了自己版本的重金属四重奏,这些工具将为人工智能编译的未来提供动力。
这四个人工智能编译器被恰当地称为“Roller”、“Welder”、“Grinder”和“Rammer”,旨在重新定义我们对人工智能模型中计算效率、内存使用和控制流的思考方式。
人工智能工具大大加快了编译时间
Roller 是其中的第一个,旨在打破人工智能模型编译的现状,这通常需要几天或几周才能完成。该系统重新构想了加速器内数据分区的过程。 Roller 的功能就像压路机一样,精心地将高维张量数据放入二维内存中,类似于铺地板。
有兴趣了解有关 Microsoft 人工智能聊天机器人 Bing 的更多信息吗?点击这里。
编译器确保更快的编译速度和良好的计算效率,重点关注如何最好地利用可用内存。最近的评估表明,Roller 可以在几秒钟内生成高度优化的内核,其性能比现有编译器高出三个数量级。
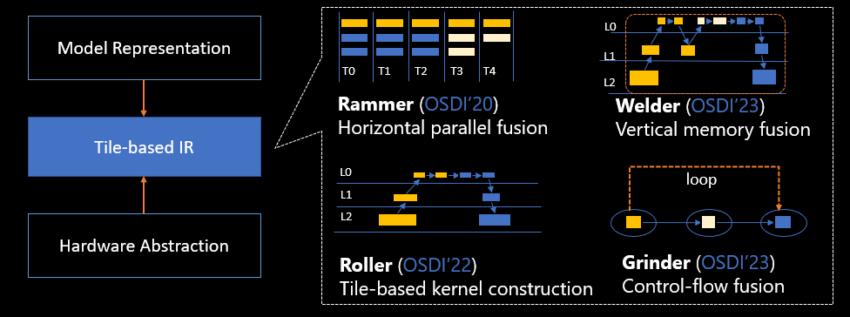
 基于统一瓦片抽象的四大核心AI编译技术 |来源: 微软
基于统一瓦片抽象的四大核心AI编译技术 |来源: 微软
Welder针对现代深度神经网络 (DNN)模型固有的内存效率问题。该编译器旨在纠正计算核心利用率与饱和内存带宽之间的不一致。
Welder 利用类似于装配线生产的技术,将计算过程的不同阶段“焊接”在一起。这减少了不必要的数据传输,从而显着提高了内存访问效率。
在 NVIDIA 和 AMD GPU 上的测试表明,Welder 的性能超越主流框架,与 PyTorch 相比加速达到 21.4 倍。
研磨机将加工速度提高 8 倍
Grinder 关注另一个关键方面——高效的控制流执行。通俗地说,它的目标是让人工智能模型更智能地确定执行什么以及何时执行。通过将控制流“磨”成数据流,Grinder 提高了具有更复杂决策路径的模型的整体效率。
想要变得更有生产力吗?我们的学习团队在此列出了 18 个最佳工具。
实验数据表明,Grinder 在控制流密集型 DNN 模型上实现了高达 8.2 倍的加速,优于现有框架。
最后,Rammer 致力于最大化硬件并行性。这是指硬件同时执行不同操作的能力。
微软人工智能编译器的这个重金属四重奏建立在通用抽象和统一中间表示之上,形成了一套全面的解决方案,用于解决并行性、编译效率、内存和控制流问题。
微软亚洲研究院首席研究员薛继龙表示:
“我们开发的AI编译器在AI编译效率方面取得了显着的提高,从而促进了AI模型的训练和部署。”
{kind=link}