

迄今的故事
零知识证明(ZKP)对于去中心化系统的重要性日益增加。ZK最初是因为在ZCash等项目中大放异彩而走入公众视野的,但今天ZK是作为以太坊的一种扩容解决方案而为人们所熟知。
利用ZK,Layer 2(例如Scroll和Polygon)也被称为Rollups,正在开发zkEVMs(zk以太坊虚拟机)。这些zkEVMs处理一批交易,并生成一个小型的证明(以KB为单位的大小)。此证明可以用来向整个网络验证该批交易都是有效且正确的。
然而,它们的用途并不止于此。ZK允许各种有趣的应用。
私有的Layer 1 – 例如Mina,它隐藏了其区块链上的交易和数据的细节,允许用户仅证明其交易的有效性,而无需透露交易本身的具体信息。neptune.cash 和Aleo也是非常有趣的项目。
去中心化的云平台 – FedML和together.xyz允许以去中心化的方式训练机器学习(ML)模型,将计算外包给网络,并使用ZKP验证计算的正确性。Druglike正在利用类似的技术构建一个更加开放的药物发现平台。
去中心化存储 – Filecoin正在为云存储带来革命性的改变,而ZK正是其核心,允许存储提供商证明他们在一段时间内存储了正确的数据。
游戏 – 更高级的Darkforest版本可能会出现,这需要实时证明。ZK可能还会扩展游戏,减少作弊的可能性。也许还能与去中心化的云平台配合,使游戏能够支付自己的托管费用!
身份 – 现在也可以通过ZK实现去中心化的身份认证。围绕这个想法,正在建立许多有趣的项目。比如notebook和zkemail(推荐了解一下)。
ZK和去中心化系统的影响非常巨大,然而,故事的发展并非尽善尽美,现如今仍然存在许多障碍和挑战。包括生成证明的过程非常消耗资源,需要进行多次复杂的数学运算。随着开发者们寻求利用ZK技术构建更为雄心勃勃且复杂的协议和系统,无论是对于证明的生成还是验证过程,开发者们会要求更小的证明大小、更快的性能和更好的优化。
在本文中,我们将探讨硬件加速的现状,以及它将如何在推进ZK应用方面发挥关键作用。
Snark vs Stark
如今有两种流行的零知识技术,即zk-STARK和zk-SNARK(在本文中我们忽略了Bulletproofs)。
| zk-STARK | zk-SNARK | |
| Complexity – Prover | O(N * poly-log(N)) | O(N * log(N)) |
| Complexity – Verifier | O(poly-log(N)) | O(1) |
| Proof size | 45KB-200KB | ~ 288 Bytes |
| 抗量子 | Yes (hash function based) | No |
| Trusted setup | No | Yes |
| Zero Knowledge | Yes | Yes |
| Interactivity |
Interactive or |
Non interactive |
| 开发者文档 | 有限,但正在扩展 | 良好 |
表1:Snark VS Stark
如上所述,两者之间存在不同之处和权衡。最重要的一点是,基于zk-SNARK的系统的可信设置依赖于至少有一个诚实的参与者参与了可信设置过程并在过程结束后销毁了他们的密钥。在链上验证方面,zk-SNARK在gas费方面要便宜得多。此外zk-SNARK的证明也明显更小,使其在链上存储更为便宜。
目前,zk-SNARKs比zk-STARKs更受欢迎。最可能的原因是zk-SNARKs的历史更为悠久。另一个可能的原因是Zcash——最早的ZK区块链之一使用了zk-SNARKs,因此目前大多数开发工具和文档都围绕zk-SNARK生态系统展开。
How to build a ZK Application
开发人员可能需要两个组件来完成ZK应用的开发
一种 ZK-friendly 表达计算的方法(DSL或底层库)。
一个证明系统,该系统应实现两个功能:Prove(证明)和Verify(验证)。
DSLs (domain-specific language) 和 底层库
在DSL方面,选择非常多,例如Circom、Halo2、Noir等等。目前Circom可能是最受欢迎的。
在底层库方面,一个流行的例子是Arkworks;还有一些正在开发中的库,如ICICLE,它是一个CUDA加速库。
这些DSL被设计用来输出约束系统。与通常的程序不同(通常以x := y * z的形式进行求值),在约束形式中的相同程序看起来更像x – y * z = 0。通过将程序表示为约束系统,我们发现诸如加法或乘法之类的操作可以用单个约束来表示。然而,更复杂的操作,如位操作,可能需要数百个约束!
因此,将某些哈希函数实现为ZK友好程序变得复杂。在零知识证明中,哈希函数通常用于确保数据的完整性和/或验证数据的特定属性,但由于位操作的约束数量较多,使得某些哈希函数难以适应零知识证明的环境。这种复杂性可能会影响到证明生成和验证的效率,从而成为开发者在构建基于ZK的应用时需要考虑和解决的问题
因此,将某些哈希函数实现为ZK友好的,就会变得复杂。
Proving System
可以将证明系统类比为一种软件,主要完成两项任务:生成证明和验证证明。证明系统通常接受电路、证据和公共/私有参数作为输入。
两个最流行的证明系统是Groth16和PLONK系列(Plonk,HyperPlonk, UltraPlonk)
| Trusted Setup | Proof size |
Prover |
Verifier 复杂度 | 灵活性 | |
| Groth16 | Circuit specific | small | Low | Low | Low |
| Plonk | Universal | Large | High | 常数 | High |
表2:Groth16 vs Plonk
如表2所示Groth16需要一个可信设置过程,但Groth16为我们提供了更快的证明和验证时间,以及恒定的证明大小。
Plonk提供了一个通用的设置,每次生成证明时,都会为你运行的电路执行一个预处理阶段。尽管支持许多电路,Plonk的验证时间是恒定的。
在约束方面,两者也存在差异。Groth16的约束大小呈线性增长,缺乏灵活性,而Plonk则更加灵活。
总的来说,要明白性能直接与你的ZK应用程序的约束数量相关。约束越多,证明者必须计算的操作就越多。
瓶颈
证明系统包含两个主要的数学运算:多标量乘法(MSM)和快速傅里叶变换(FFT)。今天我们将探讨两者都存在的系统,在这样的系统中,MSM可能占用约60%的运行时间,而FFT占用约30%。
MSM需要大量的内存访问,这在大多数情况下会消耗机器的大量内存,同时还要执行许多标量乘法运算。
FFT算法通常需要将输入数据重新排列成特定顺序以执行变换。这可能需要大量的数据移动,并可能成为瓶颈,特别是对于大的输入大小。如果内存访问模式不适合缓存层次结构,缓存利用率也可能成为问题。
在这种情况下,硬件加速是全面优化ZKP性能的必由之路。
硬件加速
谈起硬件加速,这让人回想起ASICs和GPUs是如何主宰比特币和以太坊的挖矿。
虽然软件优化同样非常重要且有价值,但它们有其局限性。而硬件优化可以通过设计带有多个处理单元的FPGAs来提高并行性,例如减少线程同步或向量化。通过改进内存层次结构和访问模式,内存访问也能更有效地得到优化。
如今在ZKP领域,主要趋势似乎转向了:GPU和FPGA。
短期内,GPU在价格上具有优势,特别是在ETH转向权益证明(POS)后,使得大量的GPU矿机闲置,处于待命状态。此外GPU还具有开发周期短的优点,并为开发者提供大量”即插即用“的并行性。
然而,FPGA应在迎头追赶,特别是在比较外形尺寸和功耗时。FPGA也为高速数据流提供了更低的延迟。当多个FPGAs聚集在一起时,它们与GPU集群相比提供了更好的性能。
GPU VS FPGA
GPU:
开发时间:GPU提供了快速的开发时间。像CUDA和OpenCL这样的框架开发者文档完善且受欢迎。
功耗:GPU非常“耗电”。即使开发者在利用数据级并行性和线程级并行性时,GPU仍然消耗大量的电力。
可用性:目前消费级的GPU价格便宜且容易获得。
FPGA:
开发周期:FPGA有一个更复杂的开发周期,并需要更专业的工程师。FPGAs允许工程师实现许多GPU无法实现的“底层”优化。
延迟:FPGAs特别是在处理大数据流时提供了较低的延迟。
成本与可用性:FPGA比GPU更昂贵,并且不如GPU那样容易获得。
ZPRIZE
如今提到硬件优化与ZKP的瓶颈,那就绕不开一个比赛-ZPRIZE
ZPrize是当前ZK领域中最重要的举措之一。ZPrize是一个竞赛,鼓励团队为ZKP的关键瓶颈(如MSM、NTT、Poseidon等)在多种平台(如FPGA、GPU、移动设备和浏览器)上开发硬件加速,评判标准为延迟、吞吐量和效率。
结果非常有趣。例如,GPU的改进非常巨大:
degree为2^26下的MSM从5.86秒提高到2.52秒,提高了131%。另一方面,与GPU的结果相比,FPGA解决方案往往没有任何基准测试,GPU结果有先前的基准测试可供比较,而大多数FPGA解决方案都是首次开源这样的算法,预计未来会有所改进。
这些结果表明了大多数开发者在开发他们的硬件加速解决方案时所感到舒适的方向。许多团队为GPU类别竞争,但只有很少一部分团队为FPGA类别竞争。我不确定这是因为在为FPGA开发时缺乏经验,还是大部分FPGA公司/团队选择秘密开发以商业化出售他们的解决方案。
ZPrize向社区提供了一些非常有趣的研究成果。随着ZPrize更多轮次的开始,我们将看到越来越多有趣的解决方案和问题的出现。
硬件加速的实际例子
以Groth16为例,如果我们检查rapidsnark对Groth16的实现,可以观察到主要执行了两个操作:FFT(快速傅立叶变换)和MSM(多标量乘法);这两种基本运算在许多证明系统中都是常见的。它们的执行时间直接与电路的约束数量相关。自然地,随着编写更复杂的电路,约束的数量会增加。
为了直观地理解与感受FFT与MSM操作到底占据了多大的计算量,我们可以查看Ingonyama对Groth16电路(在32GB扇区上执行的Filecoin的Vanilla C2过程)进行的基准测试,结果如下
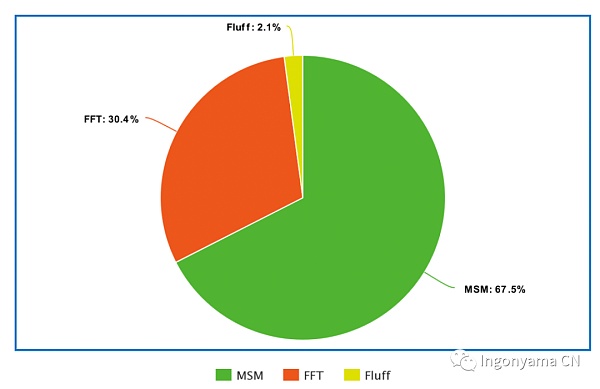

如上图所示,对于许多证明者来说,MSM(多标量乘法)可能会占用大量的运行时间,并成为一个严重的性能瓶颈,这就使得MSM成为需要加速的重要密码学算子之一。
那么MSM在其他ZK证明系统中又会占据证明者多少的计算量呢?如下图所示

在Plonk中,MSM的开销占比来到了85%以上,图片来自Ingonyama最新论文Pipe MSM。
所以硬件加速应当如何加速MSM?
MSM
在谈如何加速MSM之前,我们需要理解什么是MSM
多标量乘法(MSM, Multi-Scalar Multiplication)是一种用于计算多个标量乘法之和的算法,形式如下

其中G是椭圆曲线群中一点,a是标量,MSM的结果也会是一个椭圆曲线点
我们可以将MSM分解为两个主要的子组件:
模乘法(Modular Multiplication)
椭圆曲线点加法(Elliptic Curve Point Addition)
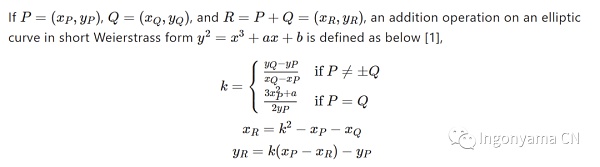
我们以Affine(x,y)类型的点为例,进行朴素的P+Q运算。
当我们想要计算P + Q=R时,我们需要计算一个值k,通过k与P,Q的横坐标从而
获得R的坐标.计算过程如上,在这个过程里面我们进行了2次乘法,1次平方,1次求逆运算,以及若干次加法 减法运算。值得注意的是,上述运算都是在有限域当中进行的,也就是mod P下的运算。实际当中,P会非常的大。
上述运算的开销为 求逆>>乘法 >平方,加减法的开销可忽略。
所以我们希望尽量避免求逆运算,因为一次求逆的开销至少是乘法的百倍。通过拓展坐标系我们就可以做到这一点,但是代价是过程的乘法数量会相应增加一些,如 Jacobian坐标: XYZ += XYZ,乘法会增加到10次以上,具体取决于加法算法。
GPU VS FPGA 加速MSM
本节将比较两个领先的MSM实现,PipeMSM和Sppark,其中PipeMSM在FPGA上实现,而Sppark在GPU上实现。
Sppark和PipeMSM使用最先进的Pippenger算法 实现MSM,也被称为bucket算法;
Sppark使用CUDA实现;它们的版本具有高度的并行性,并在最新的GPU上运行时取得了令人印象深刻的结果。
然而,PipeMSM不仅优化了算法,还为模数乘法(Modular Multiplication)和椭圆曲线点加法(EC Addition)的数学基元提供了优化。PipeMSM处理了整个“MSM堆栈”,实现了一系列的数学技巧和优化,旨在使MSM更适合硬件,并设计了一种旨在降低延迟以及重点关注并行化的硬件设计。
下面让我们快速回顾一下PipeMSM的实现。
低延迟
PipeMSM旨在在对大量输入执行多个MSM时提供低延迟。由于动态频率缩放的原因,GPU不能提供确定性的低延迟,GPU会根据工作负载调整其时钟速度。
但是由于优化的硬件设计,FPGA实现可以为特定工作负载提供确定的性能和延迟。
EC加法实现
椭圆曲线点加法(EC Addition)被实现为低延迟、高度并行且完整的公式(完整意味着它正确计算了椭圆曲线群中任何两点的和). 椭圆曲线点加法在EC加法模块中以流水线方式使用,以减少延迟。
我们选择将坐标表示为射影坐标,在加法算法上我们使用一个Complete椭圆曲线点加法公式。主要优点是我们不必处理边缘情况。完整的公式;
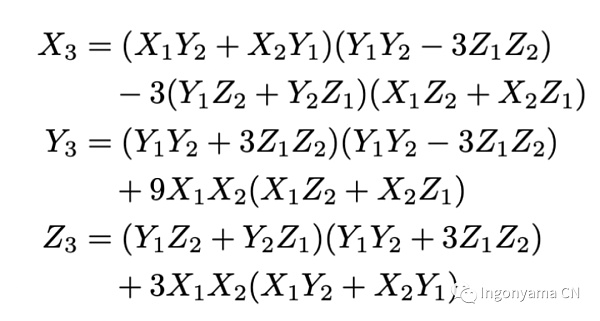
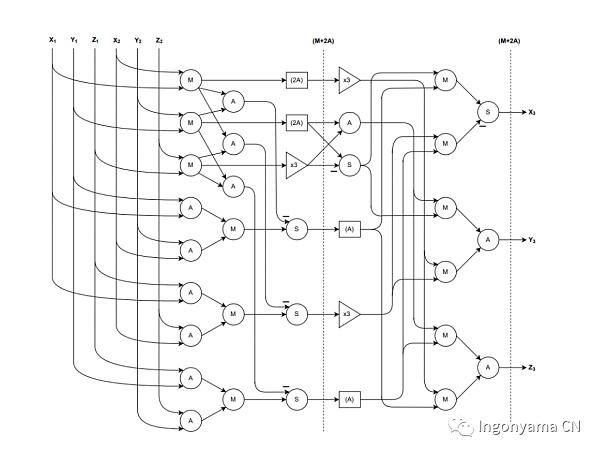
我们以流水线和并行的方式实现了这个加法公式,我们的FPGA椭圆曲线加法器电路只需12次乘法、17次加法和就能执行这个公式。而原始公式需要15次模乘法、13次加法。FPGA设计如下
模乘实现(multi mod)
我们利用了Barrett Reduction和 Karatsuba 算法。
Barrett Reduction是一种有效计算 r≡ab mod p (其中 p 是固定的)的算法。Barrett Reduction试图通过近似除法来替换除法(一种昂贵的操作)。可以选择一个误差容限来描述我们寻找正确结果的范围。我们发现,较大的误差容限允许使用较小的约化常数;这减小了模约化操作中使用的中间值的大小,从而减少了计算最终结果所需的乘法次数。
在下面的蓝色方框中,我们可以看到,由于我们的高误差容限,我们必须进行多次检查以找到准确的结果。
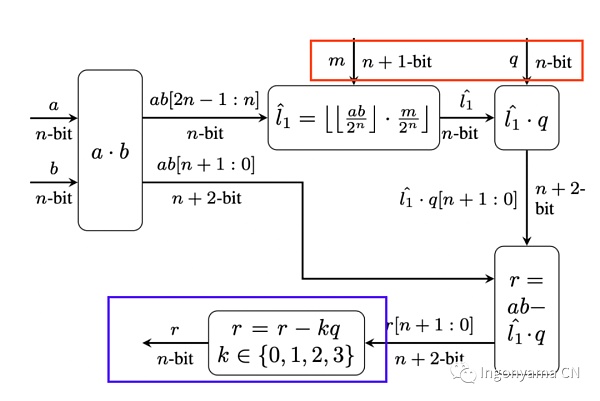
简而言之,Karatsuba算法用于优化我们在Barrett Reduction中执行的乘法。Karatsuba算法将两个n位数的乘法简化为三个n/2位数的乘法;这些乘法可以将位数简化到足够窄,直到可以直接由硬件计算。细节可以阅读Ingo的paper:Pipe MSM
利用上述算子,我们开发了一个低延迟、高度并行的MSM实现。
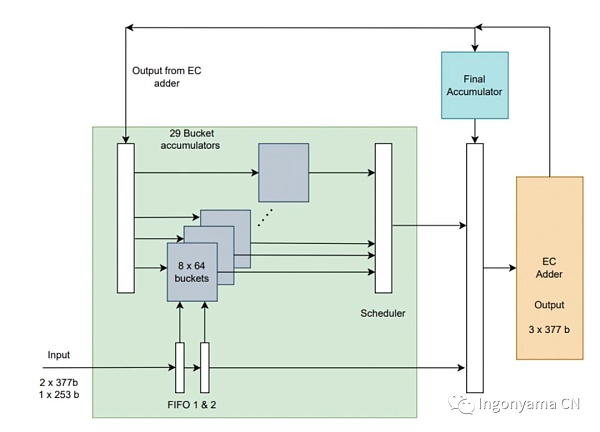
核心思想是:不是一次计算整个MSM,而是并行地将每个chunk传递到EC加法器中。EC加法器的结果累积到最终的MSM中。
最终结果
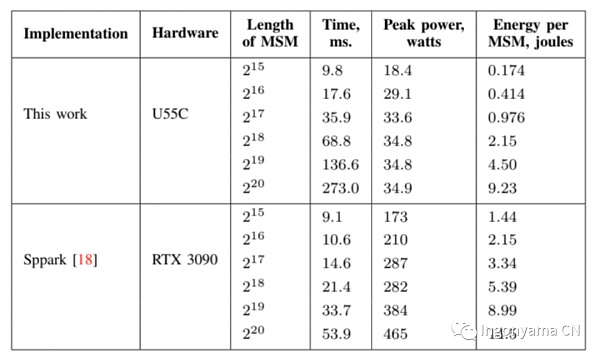
上图展示了Sppark和PipeMSM之间的比较。
最突出的是FPGA提供的显著节能效果,对于未来大规模证明生成操作来说,这可能极为重要。值得注意的是,我们的实现是在@125MHz下进行原型设计和基准测试的,将时钟速度提高到@500MHz可能会将计算时间提高4倍或更多。
使用我们的FPGA的另一个优势是,由于它们消耗的能量较少,产生的热量也较少,因此可以将它们安装在小型机箱服务器中。
我们正处于用于ZKP的FPGA工程的初期阶段,应该期待算法的进一步改进。此外,FPGA在计算MSM的时候,CPU正处于空闲状态,通过将FPGA与系统资源(CPU/GPU)结合使用,可能可以实现更快的时间。
总结
ZKP已成为分布式系统的关键技术。
ZKP的应用将远远超越仅仅扩展以太坊这个层面,而是允许将计算外包给不受信任的第三方,允许开发以前不可能的系统,例如分布式云计算、身份系统等等。
传统上,ZKP的优化主要集中在软件级别的改进上,但随着对更卓越性能的需求增加,我们将看到更多涉及硬件和软件的先进加速解决方案。
目前我们主要看到的加速方案使用的是GPU,这是因为使用CUDA的开发时间短,而且目前消费级GPU非常便宜且丰富。GPU还提供了令人难以置信的性能。所以GPU不太可能在短期内从这个领域消失。
随着更多复杂的开发团队进入该领域,我们很可能会看到FPGA在功耗效率和性能方面处于领先地位。与GPU相比,FPGA提供了更多底层定制以及更多配置选项。与ASIC相比,FPGA具有更快的开发速度和灵活性。随着ZKP世界的快速发展,FPGA可以使用不同的程序重新刷写以适应不同的系统和更新解决方案。
然而,要生成接近实时的证明,可能需要根据我们为其生成证明的系统,将GPU/FPGA/ASIC配置组合在一起。
ZPU也可能会发展,为大规模证明生成器和低功耗设备提供极为高效的解决方案(详情见之前的文章)。
{kind=link}