

本文将讨论返回动态数组的函数限制、处理方法,以及「用智能合约实现 Web2 后端」方法来构建应用程序的可行性。
原文标题:《智能合约:关于返回动态数组的问题》
撰文:Oleg Shatniuk
编译:ChinaDeFi
自从智能合约被引入以来,基于智能合约的系统复杂性增加了很多。它从简单的投票合约、ERC20 代币开始,发展到像 Uniswap、Aragon 等复杂的架构。
最近,我所在的 Custom App( 开发工作室 ) 正在开发一款 Minter Guru dApp,而我正在研究系统架构和智能合约。根据 Minter Guru 的理念,我们必须将尽可能多的逻辑转移到智能合约上。
在实现 read( 从 CRUD 模式 ) 函数时,我们遇到了返回动态大小数组的问题,该数组可能包含数百甚至数千个元素。因此,我们研究了实现此类函数的局限性。
在本文中,我们将讨论这些限制、处理它们的方法,以及「用智能合约实现 Web2 后端」方法来构建应用程序的可行性。
为了更好地理解,你应该熟悉以太坊区块链基础知识 ( 或任何其他 EVM 兼容的区块链,如 Polygon 或 BSC),Solidity 和 Hardhat。所有关于如何运行它的例子和说明的代码都可以在我们的 GitHub 库中找到。
Gas 限制
我们的第一个想法是,理论上,我们可以达到 gas 的极限。
在 EVM 中,每个函数调用都需要 gas。由于调用不会消耗真正的 gas,所以我们可以设置任何 gas 限制,但是由于 EVM 实现的最大 gas 限制等于 uint64 类型的最大值,所以就是 18446744073709551615。
让我们通过一个简单的合约例子来检查一下实现这个限制的速度。我们将使用一个简单的合约 uint256[]存储变量,推送 n 个值到数组函数和 getter 方法。此外,我们需要两个脚本来部署合约,并测试所需的 gas 限制。我们将使用 Hardhat 作为我们的本地网络并与合约进行交互。
消耗的 gas 取决于数组的大小,因为 EVM 会将数组数据复制到内存中。因此,我们将研究 gas 消耗和数组大小 ( 以字节为单位 ) 之间的依赖关系。为了简单起见,我们使用 uint256[]数组。对于其他数据类型,以字节为单位的编码数组大小的计算有所不同。根据 Solidity,Enc(uint256[])=Enc(array.size)(Enc(array[0],…,array[array.size-1]))。因此,数组的字节大小等于 size(uint256)+size(uint256)array.size=32+32array.size。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.9;
contract ReturnLimitTest {
uint256[] private array;
function addToArray(uint256 count) external {
for (uint256 i = 0; i < count; i++) {
array.push(array.length);
}
}
function getArray() external view returns (uint256[] memory) {
return array;
}
}
import * as hre from “hardhat”;
import {program} from “commander”;
import {ReturnLimitTest__factory} from “../typechain-types”;
async function main() {
program.option(“-instance, –instance <string>”)
program.parse();
const BN = hre.ethers.BigNumber;
const accounts = await hre.ethers.getSigners();
const factory = new ReturnLimitTest__factory(accounts[0]);
const instance = factory.attach(program.opts().instance);
console.log(“array size,estimated gas”)
for (let i = 0; i < 10000000000000000; i++) {
const estimatedGas = await instance.estimateGas.getArray({
gasLimit: BN.from(“18446744073709551615”)
});
await instance.addToArray(1000);
console.log((i * 1000).toString() + ‘,’ + estimatedGas.toString());
}
}
main().catch((error) => {
console.error(error);
process.exitCode = 1;
});
在运行这个脚本时,我们看到 for 循环的迭代开始变得异常缓慢。第 10 次迭代花了 10 秒以上,第 50 次花了 4 分钟以上。
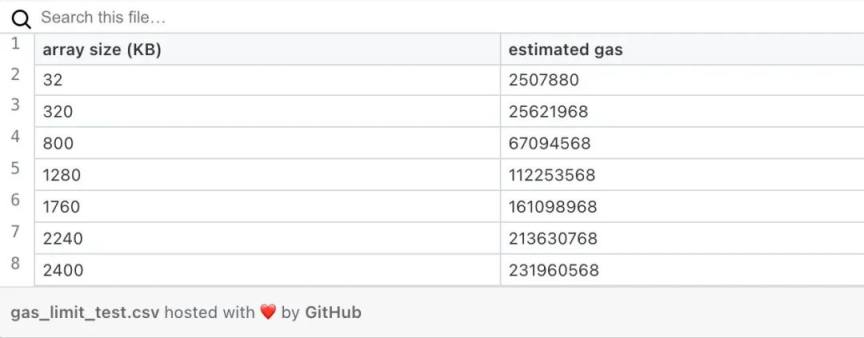

根据某些数组大小估计的 gas
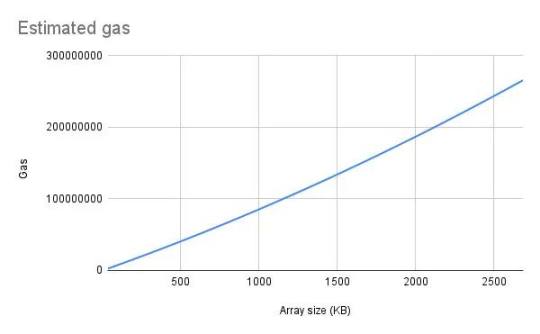
估计的 gas 依赖于数组大小
在图表中,我们可以看到估计的 gas 与数组大小呈线性关系,所以让我们建立外推来估计数组的理论大小。我们已经使用谷歌电子表格和线性回归完成了它。
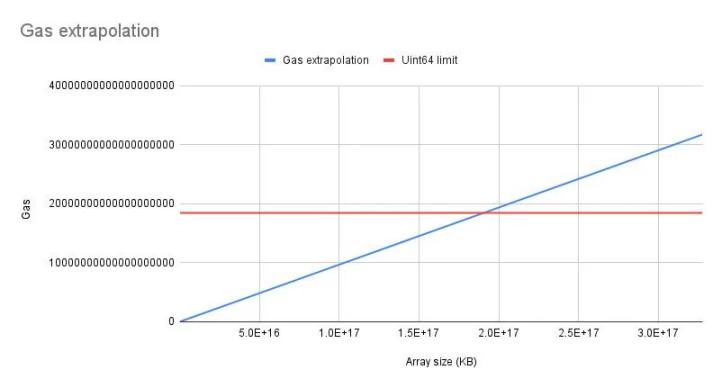
估计 gas 外推
可以看到,理论上的 uint256 数组尺寸限制大约等于 1.8e+17 千字节 (163709 千字节 ),这实际上是无法实现的。其中执行时间就是一个大问题。
执行时间
首先,我们要提到的是,我们正在用 Node.js 实现的 Hardhat 网络进行测试,所以它的性能会比在以太坊节点中使用的 Golang 实现要差。但是,与 EVM 实现语言相比,EVM 的设计对智能合约功能的实现影响更大。
进行测试的机器参数:
- CPU – 11 代 Intel®Core™i7-1165G7 @ 2.80GHz × 8
- Ram – 16GB
- 操作系统 – Ubuntu 22.04 LTS
- 磁盘 – 512gb SSD
现在修改我们的测试脚本来测量执行时间。我们只需要改变测试脚本中的 for 循环来记录执行时间。下面是代码:
console.log(“array size,estimated gas,execution time”)
for (let i = 0; i < 10000000000000000; i++) {
const start = Date.now();
const estimatedGas = await instance.estimateGas.getList({
gasLimit: BN.from(“18446744073709551615”)
});
const finish = Date.now();
await instance.addToList(1000);
console.log((i * 1000).toString() + ‘,’ + estimatedGas.toString() +
‘,’ + (finish – start).toString());
}
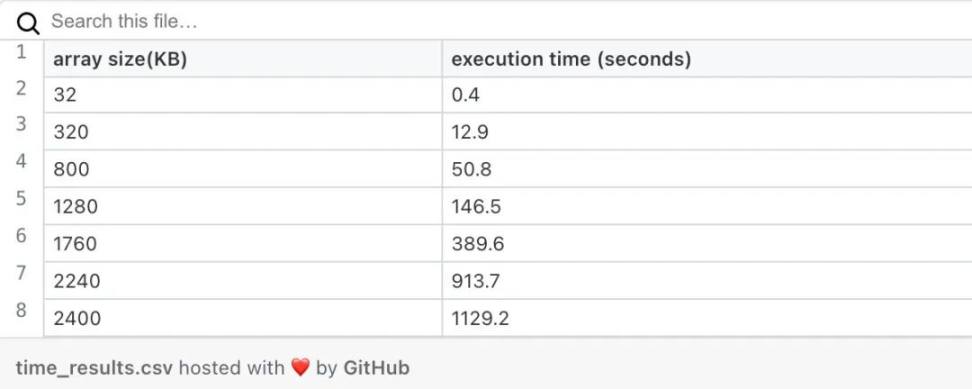
现在我们可以看到,高执行时间的问题很快就出现了。对于 320 KB 的数据,12 秒的执行时间太长了,所以时间成为我们需要克服的主要问题。
分页
没有一种神奇的方法可以在合理的时间内获得大的数组。但是,如果你的应用程序在某一时刻不需要完整的数组,你可以像在 Web2 中那样使用分页模式。然而,如果是这样,则表明存在架构问题,这是智能合约系统或经典 Web2 应用程序无法解决的。
分页通常被开发人员用来限制一个 API 调用中返回数据的大小。这种方法减少了延迟,也减少了为浏览器和移动应用程序呈现的 UI 元素的数量。
分页的实现包括以下步骤:
- 在数组上定义排序
- 将页码和页面大小添加到 API 方法 ( 本例中的合约函数 )。你的新方法应该返回数组的一部分:array[pagesize:min((page+1)size, array.length)]
- 将数组中元素的总数量添加到响应中,就可以在客户端上找到页面数量。
现在修改我们的测试智能合约,如下图所示:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.9;
contract ReturnLimitTestWithPagination {
uint256[] private array;
function addToArray(uint256 count) external {
for (uint256 i = 0; i < count; i++) {
array.push(array.length);
}
}
function getArray(uint256 page, uint256 pageSize) external view returns (uint256[] memory, uint256) {
require(pageSize > 0, “page size must be positive”);
require(page == 0 || page*pageSize <= array.length, “out of bounds”);
uint256 actualSize = pageSize;
if ((page+1)*pageSize > array.length) {
actualSize = array.length – page*pageSize;
}
uint256[] memory res = new uint256[](actualSize);
for (uint256 i = 0; i < actualSize; i++) {
res[i] = array[page*pageSize+i];
}
return (res, array.length);
}
}
测试脚本。我们还将节省每个获取页面调用的执行时间,以表明它对任何页面保持不变。这是代码:
import * as hre from “hardhat”;
import {program} from “commander”;
import {ReturnLimitTestWithPagination__factory} from “../typechain-types”;
async function main() {
program.option(“-instance, –instance <string>”)
program.parse();
const accounts = await hre.ethers.getSigners();
const factory = new ReturnLimitTestWithPagination__factory(accounts[0]);
const instance = factory.attach(program.opts().instance);
await instance.addToArray(1023);
console.log(“array size,execution time,one call execution times”)
for (let i = 1; i < 10000000000000000; i++) {
const start = Date.now();
const oneCall = [];
for (let j = 0; j < i; j++) {
const start = Date.now();
await instance.estimateGas.getArray(j, 1024);
oneCall.push((Date.now() – start));
}
const finish = Date.now();
await instance.addToArray(1024);
console.log((i * 1024 * 32).toString() + ‘,’ +
(finish – start).toString() + ‘,’ + oneCall.join(“;”));
}
}
main().catch((error) => {
console.error(error);
process.exitCode = 1;
});
让我们看看结果。同样,完整的结果可以在我们的存储库中找到。此外,为了减少表的大小,我们将只显示 get 页面调用的平均和最大执行时间:
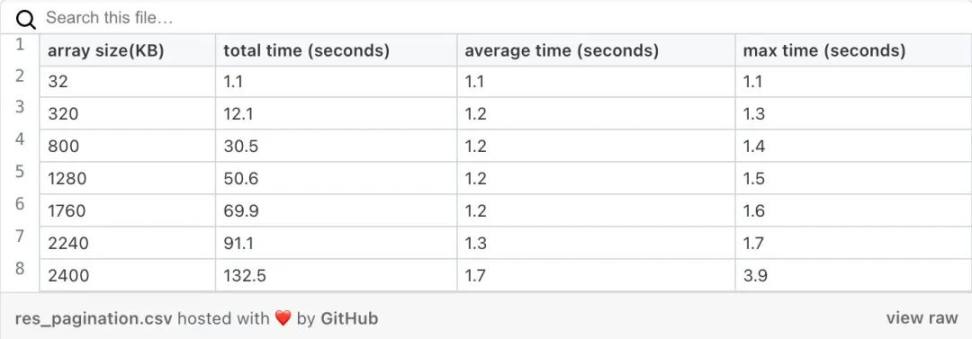
按页获取数组的执行时间
所以现在我们可以在合理的时间内得到数组的一部分。
最后一个细节:如果想要遍历可以频繁修改状态的数组,可以在调用函数时使用固定的区块号。这保证了状态在每一页调用中都保持不变。使用 Hardhat 合约绑定,可以这样做:
await instance.getArray(0, 1024, {
blockTag: 1234, // block number, hash, or tag (eg. latest)
});
结论
所以,有两个要点:
- 返回大数组的函数的主要问题是调用执行时间。
- 通过分页,我们可以使调用时间变得合理,并可以获取部分数据。如果应用程序的 for 逻辑可以同时处理数组的一部分,就可以使用该模式。
我们已经用最简单的 getter 逻辑完成了所有的测试,但是在你的应用程序中,getter 逻辑可能要复杂得多,因此在设计架构时,应该小心地将所有内容转移到智能合约。
在部署到主网后,你可能会遇到无法解决的问题 ( 如果你的合约不可升级 )。如果你觉得你的系统太复杂,无法将其全部放入智能合约中,那么将智能合约与经典的 Web2 解决方案相结合将是明智的选择。
{kind=link}