

第八届万向区块链全球峰会第四日主题为—积“土”成山,一文看尽 Oasis Labs 创始人、海南君顾数科研究院创始人、Certik 工程副总裁等精彩观点。
整理:《积「土」成山:隐私计算与数据治理》by Foresight News
TL;DR
- 《Web3 世界的安全保障》——Certik 工程副总裁 David Tarditi
- 《基于 MPC 的数字资产保护解决方案》——LatticeX 基金会首席产品官宋军
- 《自我主权身份与数据经济:建设负责的数据经济》——加州大学伯克利分校教授、Oasis Labs 创始人兼首席执行官宋晓冬
- 《数字时代的自我修养》——海南君顾数科研究院创始人兼院长单福
- 圆桌讨论:《区块链安全及隐私》——慢雾首席技术官 Blue,安比实验室创始人兼首席执行官郭宇,O(1) Labs 首席执行官 Emre Tekisalp,Nym Technologies 首席执行官 Harry Halpin
《Web3 世界的安全保障》——Certik 工程副总裁 David Tarditi
大家好!我是 David Tarditi。我是 Certik 的工程副总裁,今天我想和各位分享的主题是 Certik 如何成为 Web3 世界的安全保障提供者。
值得信任的区块链系统是当前我们所需要的,世界也需要区块链才能更加安全。如果关注区块链发展的情况,区块链已经实现了长足和快速的进展。2021 年,区块链对于世界 GDP 的贡献是 660 亿美元。而这样的贡献数字预计到 2030 年(未来十年间)会增长 25 倍,达到 1.76 万亿美元。
如果你再关注一下在 DeFi 协议中已经锁定的总锁仓价值,也就是我们经常所说的 TVL 的话,这个数字也已经增加了 23 倍。随着区块链的使用场景日益增加,我们也日益看到由于程序本身的问题而产生越来越多的损失,程序的 bug 会造成漏洞,使得黑客以及其他人来窃取资金,或者窃取具有价值的资产。
2020 年,由于黑客攻击所造成的损失达到了 5.16 亿美元,而这个数字在 2021 年的时候达到了 18 亿美元。由于黑客攻击,或者是由于程序本身的漏洞而为黑客所利用。
这张幻灯片展示的是主要三个对于区块链攻击类型,其中排名第一的类别就是对于跨链桥的攻击。这类攻击主要会产生财务上的损失,由于这些跨链桥攻击而造成的损失已经达到、已经超过了 10 亿美元。跨链桥代表的是它允许区块链之间可以进行跨链的沟通,同时也允许资产在不同的区块链之间进行转移。但是问题在于不管哪条区块链出现问题,或者跨链桥本身出现了问题,黑客都可以利用这样的漏洞。 比如说在之前的攻击事件中,黑客本身创建了恶意的交易,从而实现了对跨链桥的攻击。
而对于区块链第二个主要类别的攻击是针对智能合约本身的漏洞,智能合约在区块链上运行,可能会出现一系列的漏洞,这些漏洞可能就会为黑客,或者是其他类型的攻击者所利用。比如说我们经常看到的一种漏洞是对于输入值没有验证,也就是不对于输入值数据的正确性进行验证。缺乏访问控制,访问控制代表的是你如何保证那些没有访问权限的人不能做敏感的操作,比如说铸造或者是销毁这样比较敏感的操作。有时候,如果这一类函数、这一类功能权限没有得到保护的话,就会造成损失。
第三个针对区块链攻击的主要类别就是治理攻击,治理代表的就是对于区块链和智能合约具体管理的一种方式,一般来说,对于智能合约有两种治理的方式,其中一类就是由项目方自身对于智能合约进行管理。而第二类主要就是通过社区进行治理。比如说,如果攻击者能够掌握智能合约的治理,能够治理智能合约的话,那他就能够改变智能合约关键的参数,或者改变智能合约本身运行的逻辑。比如智能合约允许在关键紧急情况下将资产取出,但如果黑客利用了这样的功能,有可能就直接将资产取出。
除此之外,还有一些更加微妙的漏洞,也可以导致黑客去控制智能合约中一些物品、资产的价格,或者其他的费用。所以大家看到,由于一系列的程序错误和漏洞而导致了在区块链世界中出现了巨大的财务损失。如果真的要实现大规模采用的话,非常有必要提升区块链的安全性。
所以,我希望和各位分享一下桥水基金创始人 Ray Dalio 曾经说过的一句话,如果说网络攻击比网络防御更强大的话,作为拥有网络资产的人,我不能忽视网络攻击的风险。也就是说,在维护关键安全性软件方面,是存在巨大挑战的。再反观当前的环境,不管你是使用个人电脑、Web2 还是使用云,安全性保证不及 90% 的。再反观一下在传统世界里,人们可以做的是对系统进行监控,来确保系统使用方式是正确的,也可以进行主动的防御。如果说发现系统中出现一些漏洞的话,他们可以主动采取措施打补丁解决这些问题。最常见的就是打补丁,在漏洞和打补丁之间,双方存在一种和时间赛跑的竞赛。
如果说,你作为攻击者没有办法操作系统底层代码的话,那你可能就进行黑匣子的攻击。但看一下区块链世界、Web3 世界的话,大家必须要有意识,这样的技术代表的是一种全新的技术栈,这也就意味着可能本身就会引入一些新的问题,就因为它的技术本身就是全新的。
第二个问题在于区块链代表的是没有任何人能够单方面制止的世界计算机,所以区块链是由一系列网络、一系列计算机所组成的大型网络。这个网络越大,区块链就越安全。但问题在于,你没有办法凭个人之力单边阻止区块链的运行。并不像在个人电脑世界、Web2 世界里你可以做主动防御。在 Web3 和区块链世界里就不行了。
因为在 Web2 的世界里,如果出现极端情况的话,你只需要断网就可以,但是在 Web3 世界里不存在断网这一说。另外,Web3 的问题在于智能合约很难修改,因为在默认的情况下,智能合约就是不可篡改的,所以大多数区块链下你也不希望对智能合约做任何变更。因为智能合约的不可篡改性就是区块链存在的基石。
反观一下在传统世界,如果你的个人电脑出现漏洞的话,你可以打补丁。但是智能合约的世界里,你没有办法给智能合约打补丁。除此之外,Web3 和 Web2,以及区块链和 Web2 相比,还有两个不同的点:
第一点,大多数区块链和智能合约代码都是开源的这也意味着黑客和攻击者能够阅读底层的源代码,并且识别其中的漏洞。但是在 PC 和 Web2 的世界里,情况是不一样的。
第三点,区块链单个漏洞可能会造成巨大的损失,可能会造成千万美元级的损失。到目前为止,整体损失高达数亿美元,而与之相比在 PC 以及 Web2、云的世界里,这样攻击所能造成的损失并不是非常大。如果你的电脑被攻击的话,你所需要做的只是重装计算机操作系统,或者有几天你的数据是丢失的。
将软件层面和硬件层面进行对比,如果说你关注 CPU 硬件的话,CPU 硬件安全性往往是超过 99% 的,CPU 硬件依赖于形式化的验证,形式化验证之所以有必要是因为如果像 CPU 这样的硬件被交付的话,一旦他们在在途或交付之后想要变更的话,就会成本非常高。所以在 CPU 的世界里,像 meltdown 和 spectrum(音)花了 22 年的时间才最终被人们发现。但是,与之相对比的是软件侧的问题,当前对于软件中的并发理论依然处于非常早期的阶段。比如说如果观看一下软件当前的复杂性,对于软件复杂性的认识还处于早期阶段。
Certik 所做的是将网络安全与形式化验证进行结合,通过将网络安全和形式化验证结合之后,为区块链和 Web3 项目提供安全性保证。参考了过去在硬件世界中所做的对于硬件安全提供保障的方法,并且应用到区块链和 Web3 世界,从而实现超过 99% 的安全性保证。到目前为止,已经为超过 3000 亿美金的加密资产提供保证,有超过 3200 的客户,平均每个月要做超过 250 个代码审计。如果大家比较关注 DeFi 项目的话,你会看到在 CoinMarketCap 上面所列出来的 DeFi 项目,所有找了第三方审计的项目中,有 70% 的市场份额。因为不是所有在 CMC 上列出的项目都会找第三方审计服务。总的来说,在所有 rarketplace 上列出来的项目我们有 12% 的市场份额。但是在那些未找第三方审计机构做代码审计的项目中,有 70% 的市场份额。
接下来想和各位分享 Certik 到底如何为区块链和 Web3 打造最强大的安全性保证,首先我想和各位介绍的是 Certik 团队。
Certik 创始成员是由 Gu Ronghui 介绍和 Shao zhong 教授,其中顾教授是哥伦比亚大学计算机学的教授,而邵教授是来自于耶鲁大学计算机系的系主任、副教授,同时两位教授与耶鲁大学合作,共同创办了 Certik。邵教授同时也是在验证和确认软件方面的专家,他在相关领域拥有超过 25 年的研究和工作经验。
顾教授则是经过验证的并发操作系统主要设计者和开发者,CertiKOS 本身就是非常了不起的成就,因为它是世界上首个完全经过验证的多核操作系统和 hypervisor 监视器。CertiKOS 被部署到无人地面车辆上,所以它本身就是巨大的成就,你能够开发出经过完全验证的多核操作系统和 hypervisor。
根据康奈尔科技学院院长兼副校长 Greg 的说法,十年前没有任何人预测到我们可以证明一个单线程和的正确性,更不用提现在要把它应用到多线程和之上。所以说,邵教授领导团队为我们树立很好的榜样。
CertiKOS 本身就是巨大的成就,也在研究界、学界获得了许多的认可。比如说幻灯片上所示的 SOSP2019,以及 OSDI2021 最佳论文奖。这两个会议都是操作系统以及软件开发领域顶尖的会议。除此之外,与 CertiKOS 相关的工作也获得了三个亚马逊研究奖项,另外也得到了 ACM 的重点推介。
除了两位教授本身外,像 Jason 是首席计算机科学家,首席操作系统科学家,他拥有计算机科学的博士学位,同时在相关行业有超过 20 年的工作经验,其中包括工程、产品开发,以及运营。
我自己本人是卡内基梅隆的 PHD 博士,我在微软有 25 年的工作经验。之后我就加入了 Certik,并且担任 Certik 的工程副总裁,我在编译器以及编程语言方面是专家,同时也是安全性和操作系统方面的专家。
Villelm Sjoberg 博士是首席科学家,他毕业于宾夕法尼亚大学。2016 年获得了宾夕法尼亚大学博士学位。他之前就担任邵教授的研究助理,后来也加入了 Certik,他是软件验证、编程语言、类型系统方面的专家。除了管理团队本身经验非常丰富,技术背景深厚之外,团队的其他成员教育背景也是可圈可点的。团队有超过 180 名工程师,和 30 名以上的数据科学家。其中超过 18% 的员工是博士,25% 的员工是从常春藤学校毕业,而 41% 的员工曾在美国就读排名前十的计算机科学大学。
接下来一个问题是 Certik 到底如何为区块链和 Web3 提供安全保障?理念就是提供端对端的安全,覆盖整个区块链和 Web3 的生命周期。主要包括三大模块:
- Audit,审计,提供静态保护。
- Skynet,提供动态保护。
- Leaderboard,排行榜,主要是为社区提供透明度。
对于审计的想法是,即便软件被创建后,再被部署到区块链之前做区块链之前,从而确保软件程序本身没有漏洞。但是,在软件被部署到区块链之后,我们使用 Skynet 来提供动态保护,主要是进行监控,看一下是否有不同寻常的交易,或者寻找新的攻击类型,是否会影响到已经部署好的软件。而排行榜主要是帮助社区了解区块链系统总体的安全性情况,我刚刚已经提过了,为超过 3000 亿美元的数字资产提供安全保障,这些资产横跨了 DeFi、NFT、元宇宙、平台。
所以,下一个问题是 Certik 到底如何保护项目,如何防止防御一些漏洞呢?首先,会对于源代码进行彻底的人工审计,除此之外也用软件模型检查形式化的静态分析和机器学习相结合的软件模型做自动化的代码审计。人工审计主要是为了寻找在设计过程中一些不同寻常的问题,或者由于引用了新的区块链产品而引入的新问题。而这些软件检查工具本身主要是为了寻找已知的问题。通过将人工审计、软件自动化审计相结合,就能对软件和程序进行非常彻底的代码审计。除了对于软件模型检查之外,也提供形式化验证,也就是说,用纯数学的手段证明代码的正确性。
这张幻灯片展示的是审计报告最终看起来是什么样子的,比如说我们审计的项目是 Sandbox 这家元宇宙公司,找到了 6 个问题,一个是 major(严重),一个是 medium(中等),还有一个 minor(不是很严重),这代表了漏洞的严重程度,如果是 critical,也就是排名第一的重大的话,这就意味着你的程序可能很快就会被攻击,而 minor 是最轻微的,意味着哪怕被攻击了,损失也不会非常严重,或者漏洞不是那么容易被黑客利用被攻击。
通过这样的方式,在 Sandbox 项目里,将相关的漏洞告知给项目方,让项目方进行调整,从而消除或者降级漏洞。这张幻灯片显示的是到底如何进行代码审计。
首先会对软件进行运行,另外也会用人工对代码进行手工审查,对于已经发现的问题进行再次审计。比如说这张幻灯片显示的是一行一行代码去检查,包括在人工审计过程中、软件审计过程中发现了问题,都对代码一行一行的检查。通过这样的方法来判断是否有漏掉问题,找到的问题是否是对的。将找到的漏洞提交给相关项目方,从而使得他们能够进行漏洞的修复。
正如我刚刚跟各位介绍的,平均每个月要完成 250 个新的代码审计,每个月要审计超过 500 万行代码,每个月都会识别出超过 3000 个漏洞。审计的问题在于是静态的一次性的,但是如果说智能合约被部署完之后再发现软件有漏洞怎么办?这就是为什么我们需要有 Skynet 动态审计系统,主要是提供动态的监控,动态监控系统主要监控的是两件事情:
第一是交易,从而使得我们可以识别可疑的交易,并且在几秒之内就发出警告。关注那些有可疑行为、问题行为的账户,也非常关于资产过于集中的问题,因为资产过于集中可能表明某一个 DeFi 系统、某一个智能合约系统可能会出现一些金融上问题。到目前为止,自 2021 年以来,Skynet 已经有超过 600 个企业的订阅。
Skynet 监控的第二个问题就是监控项目的代码、智能合约本身,包含了静态分析。
我们所使用的是最新板块的静态分析工具,同时也关注社会情绪,比如说治理是否有问题?项目方对于安全性问题的响应程度如何,响应速度如何?通过 Skynet,人们就能够真正地了解一个项目持续性的安全情况,可以对项目持续性安全情况进行监控。
对于普通人来说,对于没有技术背景的人来说,很难判断一个智能合约本身是否安全,很难判断区块链系统本身是否安全,这也是为什么我们有「安全性排行榜」的原因,安全性排行榜在网站上展示,通过排行榜对于项目安全性进行评估,然后给每个项目赋以不同的安全性评分,在网站上列出安全性排行榜,任何人只要感兴趣的话,都可以去我们的网站上查看排行榜,并且找出具体项目的安全性评分。
到目前为止,排行榜上已经列出了 2912 个项目,如果大家感兴趣的话,也可以去我们的网站上查看,具体的网址已经列在了幻灯片左上角。如果想要了解 Certik 在区块链及 Web3 领域主要有哪些客户。正如我刚刚提到的 CoinMarketCap 上排名前 200 的项目,65.4% 的项目是我们的客户,另外排名前 500 的项目中,有 68.6% 是我们的客户。
所有在 CoinMarketCap 上,只要他们找第三方审计,这些项目中 71.9% 是我们的客户。再看一下季度性增长,大家可以看到,季度增长已经超过了 1200 个百分点。
最后想和各位介绍一下投资者,得到了区块链以及其他领域领先的投资者和风投机构的支持,比如说像红杉、老虎环球、软银,还有在金融领域的高盛也投资了我们。投资者也包括区块链行业的领军机构,比如说像 Coinbase 和 Binance 等等。
我的演讲到此结束,再次感谢各位的聆听,如果大家想要了解更多的信息,可以去我们的网站,网站上有各类视频及相关信息,以及很多可供大家了解的资料。
Certik 的使命是从现在开始保护你的社区和组织。如果大家感兴趣,可以去我们的网站,也可以通过在这张幻灯片上展示的邮箱来联系我。感谢!
《基于 MPC 的数字资产保护解决方案》——LatticeX 基金会首席产品官宋军
大家好!我是来自于 LatticeX 基金会的 Kyle。今天将跟大家分享的话题是基于 MPC 的数字资产保护解决方案,所以会花 20 分钟左右的时间介绍协议的背景、场景、应用的方式。
首先回顾一下,目前在数字资产、数字钱包领域面临的困境,以及现在尝试的解决方案是什么。从行业目前的现状大概有三类钱包去保护数字资产。
第一种,像 MetaMask 这种离线钱包,它存在的问题主要是要记很多助记词,同时它更多依赖于链上合约去管理私有的产权、资产安全。主要安全模型是基于合约的逻辑。在前几年也出现了 Noe-Custody Wallet,这种 Wallet 主要利用两方 MPC 协议,叫 TSS 以及门限签名的协议来保护数字资产。
但在两方协议当中,有一个瓶颈,如果有两方,那么其中有一方基于(2.2)的门限,其中有一方丢失的话,也会导致密钥的丢失,所以存在局限。所以我们就在思考,在目前这种离线钱包、合约钱包,还有两方 MPC 钱包中,有没有一种新的解决方案呢?既可以尽量降低用户去记助记词,同时也有更加安全程度的保护。这就是我们今天想去探讨和分享的话题。
看一看目前的解决方案,总体来说还是有两类的,大概的思想是希望把有一把私钥控制的资产转移,变成多把私钥 / 多个私钥之间权限分离的体制。左边主要是传统的 Multi-Sign,比如说 Bitcoin 的多签脚本,可以实现多把私钥控制一个资产。右边主要讲的是基于密码学的 MPC 协议,在细分领域叫 TSS 协议,这个协议本身主要是基于密码学原语的方式实现一把私钥多方计算的产生,以及私钥的签名,这是两种在目前行业内比较通用的工具。
稍微对比一下这两种方案的优缺点是什么,以及面临的场景是什么样的。
- Multi-Sign。
Multi-Sign 的方式比较简单,好处是很容易实现,但它也存在很多问题,比如说每一条链都需要做兼容,在 EVM 兼容、EVM 不兼容的链上,部署成本就比较大。
二是基于合约的逻辑,所以比原生转账的 Gas 费成本会更高。
三是很多安全都依赖于合约去实现,所以合约本身的逻辑性,以及合约本身的安全度都会影响我们的资产安全。用密码方式去实现多把私钥的管理,好处就是是链下发生的,所以跟合约没有本质的关系。Gas 费成本会比较低,而且所有安全性都是密码方式保护它,所以安全性是嫁接在离线密码的算法实现和密码工程实现的角度。
- TSS。
但目前 TSS 也存在一个问题,在我们做多方,特别是三方以上,进入行业生产系统中还存在安全和性能的瓶颈,这些性能瓶颈导致现在很多 TSS 协议没有办法直接应用到生产领域里,这是目前能够用到的工具去解决钱包的安全性,或者说数字资产安全性的话题。
可以设计一种(2.3)的体制实现资产的保护,这是一种非常典型的角度,假设说有 3 把私钥,那么一把在浏览器,里面是 Kayshard-1,另外再拆分成两把,一边是在热服务器,另一边是冷备服务器。在这种模型下,刚好形成了很好的恶意相互抵抗的模型。
但是这里面也有一个问题,在理论上这个方案是可行,但是在实际过程中钱包服务器和备份服务器还是希望形成权限的分离。在实际过程中,更多是依赖于商业上做保护。
在模型下,是比较通用,比较理想的模型去解决钱包的权限管理,以及数据资产备份以及安全密钥丢失的问题。目前在这个模型下会遇到一些瓶颈,典型的例子就是在三方介入的 MPC 密钥签名协议和两方会有比较大的区别,在实际生产环节中也跟很多项目方做过联合测试。会发现三方以上,包括在浏览器端会严重降低 MPC 协议的效率,甚至产生一次账户 Keygen 的过程需要 30 秒以上的时间,这种用户体验是比较差的。假设说在形态比较弱的情况下,可能会导致签名失败或者密钥产生失败,本质上还是一种在弱环境下、弱计算环境下,目前的 MPC 协议效率是比较低的,这也是今天想和大家分享的特点,如何提高 MPC 协议本身在这个领域里的算法效率问题。
LatticeX 基金会单独有一支研究团队和工程团队,专注在 MPC 里的 TSS 协议研究、设计和工程实现,并且也开源了现在的代码供大家去使用。接下来会重点分享在这个领域里做了哪些改进,哪些设计方案的改进,还是说算法性能的改进,这是我们着重想跟大家探讨的话题。
已经把代码开源了,在 Github 上,大家可以免费获取到代码。代码本身是基于 Rust 语言写的,在开源的实现里,已经实现了 ECDSA 的算法,因为对于大部分数字资产签名来说,ECDSA 是非常常用,严格说应该占了 70%80% 以上的场景化,未来 ECDSA 都会陆陆续续开源给大家使用。
在整个算法里,大致实现了比较简单的场景:一是密钥的场景;二是签名的过程。在密钥产生和签名过程中其实都做了改进,在密钥产生环节,理论上和工程上做了测试,因为我们在算法层面和工程层面都做了很多优化,所以比经典 7718(音)那篇论文的协议大概能快到 8 倍、7 倍左右的算法效率,这样的话就可以把一次 Keygen 的时间从原来的 30 秒拉到 2 秒、3 秒比较高效的时间,这样就更容易用到生产系统。
在签名的过程中,利用到 offline 预计算的过程,因为在原来的论文里 MPC 需要非常多轮次的交互,这样的交互在网络比较复杂的情况下,会带来多次网络时间的延迟。其实我们可以把多方计算式的签名拆成跟消息无关的 Offline 预计算过程,和消息 / 转账金额有关的 Online 的最后一次签名过程。
在过程中,特别适合钱包,或者 TPS 不是很高的场景,可以提前缓存很多组的预计算,当用户在真正签名的时候,只要推动 Online 的那一步就可以了,在这一步上可以最大程度降低用户在真正转账签名时遇到的算法和性能瓶颈,让他用起来感觉就像一次正常的单方计算、单方签名一样的用户体验。
同时,为什么我们的协议会比之前的协议带来很大的提升?简单说明一下,大概这篇论文发表在 ASIACRYPT 上是在 CCR+20 基础上做了改进,在 CCL+28(音)的协议里更多是基于 paliya(音)同态的算法,Paliya 同态(音)本来是计算量相对比较复杂的体制,所以会导致在 Keygen 的过程中产生很重的验证或者安全边界检查的辅助行为。比如说 Ready proof(音),或者说一些交换机教研的过程。这个过程会导致签名、Keygen 都比较慢。
这篇算法论文用的是私钥的同态加密,私钥的同态加密会有更多的好处。比如说在同一个域上进行操作,所以在做整个 Keygen 的时候可以做到更快,这也是理论性的基础。同时也做了一些安全边界的优化,所以在做签名的时候,相对来说有一定的优化基础,这是论文的背景。
行业内很多人都在探讨如何改进 TSS 协议本身的过程,但是我们还是希望在很好的理论基础下,比如说协议经过了大规模学术挑战,然后再用到生态环境中,这样的好处是得到充分的理论保证,得到业界很多比较好的学术高水平挑战之后,再用到实际工厂生产过程中,这是 LatticeX 基金会在 MPC 领域做的工作。当然,今天分享主要是 TSS 协议,它跟资产安全是做紧密关联的,本质也是多方计算的模式。
除了 TSS 协议本身带来的优点之外,可以把一把私钥拆成多方。实际上在真正的工厂生产过程中,不可能简简单单用一个 TSS 协议就可以了。所以在原来的 TSS 基础上,不断衍生出生产环境是生产场景。一个比较简单的概念是尝试构建端到端的密钥安全生命周期管理模型。在原来的钱包领域,比较简单的应用是创建一个账户就代表一个私钥,签名就代表使用它。一般来讲,当我们不再使用的时候,就尝试删除私钥体系。
但有些比较严格的场景,像大规模托管,或者更加 To B 的应用场景里,更多考虑的是它非常严谨的一套模型。做了以下几个设计点:
第一点,在 Key 下的每一个分片领域,二次设计时的安全性是怎么考虑的?可以基于一些 HSM 数字加密机、密钥管理系统去保护单个节点里的 Keyshard 内容,在浏览器端、移动端可以利用可信计算技术保护 Keyshard,这是一个考虑点,还是要把 Heyshard 和原来的 KMS、HSM 做整合,以此达到更好的效果。
除此之外,还在生命周期上希望管理整个流程,在每个管理流程里加入到权限控制的领域里。假设在三方场景里,大概就是这样去设计它的整个模式和系统的特点。其实,未来还会考虑到 MPC 的方式如何兼容到原来经典的安全合规模型,在原来经典的 HSM,或者 KMS 里,已经设计非常好的最佳实践。我相信这也是大家不断完善的过程,把单点的私钥保护体系变成 MPC 的方式去保护,这也是我们即将要去做的方式。
整体来看,在 MPC 领域,更多关注的是如何利用 MPC 技术解决好私钥安全,以此带来更多的未来场景拓展,使 MPC 带来的数字资产领域得到一些新的范式,更多是依赖于多权限、多方的协同管理,降低单点风险,以此提升更好的用户体验,带来更好的 Web3 入口。
这是我今天要跟大家分享的内容,谢谢大家!
《自我主权身份与数据经济:建设负责的数据经济》——加州大学伯克利分校教授、Oasis Labs 创始人兼首席执行官宋晓冬
大家好!我是宋晓冬,我是 UC 伯克利分校的计算机科学教授,同时也是 Oasis Labs 的创始人,非常感谢万向的邀请。
众所周知,数据是现在经济重要的驱动力,同时也是机器学习的命脉。目前,我们每天看到有越来越多的数据得到收集。对于个性化数据的价值来说,它现在占 GDP 的占比已经达到了非常高的水平,全球数据经济也呈现了指数级增长。然而,在很多数据中,很多都是非常敏感的。如何使用这些敏感的数据?已经给个人、机构带来了前所未有的挑战。
对个人而言,个人已经丧失了如何使用自身数据的控制权,经常他们自己的个人数据被出售或者被滥用,但是自己却不知情,也没有同意。经常大家会听到说用户的数据被他人使用,前提就是他们的数据已经被匿名化了。然而,大量研究表明,数据的匿名化本身是不足以保护用户的数据隐私的。比如说这张幻灯片展示的是《纽约时报》曾经所做的案例研究,他们通过研究的方式证明了从一个匿名的手机位置数据集之中,是能够追踪到前总统特朗普特勤局特工的位置,以及前总统特朗普本身的所在地。机构持续遭遇大规模数据泄露的困扰,很多此类攻击中,攻击者甚至窃取到了数亿甚至数十亿用户的敏感信息。
最重要的一点是,由于隐私问题,许多有价值的数据仍然被困在数据孤岛之中。也就是说,没有办法得到有效的应用。随着数字经济、数据经济的发展,这些问题未来只会变得更加严重。因此,我们迫切需要一种新的范式,我将这样新的范式称为「负责任的数据经济」。负责任的数据经济定义是什么?负责任的数据经济想要实现的目标是什么?遵循的原则是什么呢?
首先,我们必须要建立和执行数据权利,这样的数据权利构成了数据经济的基础,同时也有助于防止数据的误用和滥用。同时,也要确保数据创造价值之后可以公平地分配,从而使得用户能从自己的数据中获得足够的收益。最好的是需要实现有效的数据使用,从而最大程度提高社会福利,提高经济效率。
为了建议负责任的数据经济,需要做出范式转变。当前 Web2 世界是以平台为中心,提供的是中心化的解决方案范式。但是,我们需要转向 Web3 的新范式,应该是去中心化的,以用户为中心的。
先看一下在数字世界中关键的控制点,在数字世界中,需要访问资源数据,同时也要对数据进行计算。但是,这些不同的控制点是由不同机制所控制。首先有身份和访问控制,同样也有数据使用控制。在 Web2 世界中,所有机制都是由中心化的第三方控制。用户的身份往往是被服务提供者管理。用户数据一般被放在集中化的数据中心(数据孤岛),用户的数据往往是在自己不知情的情况下被机构使用。因此,在 Web2 的世界里,用户完全无法控制自己的数据。
在 Web3 的世界里,我们希望实现这样的范式变更,从中心化的控制到去中心化用户控制的转变。而这一切都是通过去中心化的身份、去中心化的访问控制,以及合规的去中心化计算来实现。这样一来,就可以实现自主身份、自主数据访问、自主计算。也就是在 Web3 的世界里,用户可以在不依赖任何中间机构的情况下控制自己数据的使用方式。
先看一下去中心化身份,也就是所谓的 DID。一般来说,用户用自己的用户名和密码作为身份验证的工具,在 Web2 的世界里,用户经常会依赖于第三方服务提供商来帮助他们进行身份管理。然而在 Web3 的世界里,去中心化的身份就意味着用户可以控制公钥加密方法来控制自己的身份。从本质上来说,用户可以使用自己的身份,控制自己的身份,只要他们能够控制自己的私钥即可。
因此,有了去中心化身份,我们就可以使用更加先进的技术,能做更多的事情,实现更多的功能。尤其是我想和各位简单分享一下最近所做的项目。这个项目主要聚焦的就是匿名凭证。有了匿名凭证,对用户而言,就可以获得相关的凭证颁发机构,以保护隐私的方式获得凭证的颁发,用户可以用这些匿名的凭证来证明自己的某些属性,因为这些属性在他们获得证书凭证之前就已经得到了证明,用户同样可以以保护隐私的方式来使用这些凭证,从而使得他们在整个过程中保持匿名,但是同时也可以证明。比如说自己超过了 18 岁,已经成年了,也可以证明自己的其他属性。
在最近 SNAC 的工作研究中,构建的第一个基于 zkSNARK 的匿名凭证,从而实现高效的链上验证。在这个研究里,用户获得了所颁发的匿名凭证之后,就可以生成证明。比如说证明自己已经超过 18 岁,或者证明自己是 UC 伯克利的学生等等。有了证明以后,可以通过智能合约在区块链上进行验证,用户就可以使用某些服务,因为他们已经证明了自己拥有某些所需要的属性。
同样,利用先进的密码学。比如说利用证明递归(音)对证明进行批处理,从而进一步优化对于这些匿名凭证的链上验证效率。也充分支持撤销以及对于凭证进行审计,包括对于发证机构,以及对于匿名性进行撤销或者审计。所以这是很好的使用场景,因此基于 zkSNARK 的链上验证和证书凭证颁布,主要就是可以在 DeFi 中做 KYC,因为在这样的情况下,用户可以做 KYC 获得相关的凭证,凭证是匿名的,但是可以表明用户已经通过了 KYC。现在用户还可以利用匿名凭证加入链上 DeFi 服务,使用链上的 DeFi 应用。同样,他们可以证明自己已经完成了 KYC。一方面,保护了用户的隐私,另一方面,也符合了合规性的要求。
有了新的加密学方案,也实现了相比于之前的非基于 zkSNARK 方法数量级的性能提升。而且解决方案也使得首次 DeFi 上可以做 KYC,这就是自我主权身份和匿名凭证如何帮助用户保持对于自己身份的控制,同时也能够以一种保证隐私的方式使用其他服务的很好范例。
用户到底如何通过数据和对于数据的计算来解锁一些其他的功能?首先,要实现自我主权的数据和计算,需要开发新的解决方案,在 Web2 中的传统解决方案本身是不足以满足这样的要求,在传统的 Web2 中只有两种解决方案:一是数据,只有在不被使用,或者在发送过程中被加密,也就是说只有在不被使用和发送过程中得到了保护,但是一旦数据得到了使用,或者是在使用后被复制的话,数据所有者很难对于这些过程进行控制。
我刚刚已经提到了数据匿名化往往是不足以保护用户数据隐私的,同样的道理,在 Web2 的世界里,用户也没有办法控制如何对自己的数据进行使用。相反,在 Web3 的世界中,我们需要开发全新的技术来实现数据的保护,在使用中保护数据。
这又包含了几个不同的层面:首先,需要控制数据的使用,不允许没有权限的人对于原始数据进行复制,做计算的时候也不需要复制原始数据就可以完成,第二层面需要保护计算输出值不会泄露敏感信息,并保证数据的使用合规性。通过这样的功能是,用户就可以控制对于自己数据的使用,而不需要依赖于任何第三方。
幸运的是,我们在负责任的数据技术领域,不管是从研究还是从实践的角度,都看到了迅速的进展。许多不同类型的技术可以被结合在一起,从而帮助我们实现负责任的数据使用,包括安全计算。比如说使用安全硬件、密码学的方法,比如说 MPC、安全多方计算,以及完全的同态加密等等,这些安全计算在计算过程中就可以保证数据的保密性。
差分隐私也可以保证计算的输出不会泄露有关于输入值的敏感信息,联邦学习则支持分布式的数据分析和机器学习,同时保证数据不会离开用户的数备。加上分布式的账本,就可以提供有关于数据使用的不可篡改的日志,从而确保数据在使用过程中始终是合规的。
给各位举一个例外真实世界的例子,通过这样的例子,希望给各位展示的是安全计算技术如何帮助用户,始终保持对自己数据的控制。与此同时,也能够保证以一种保护隐私的方式数据可以得到使用。这是我们最近做的一个项目,是由 Oasis Labs 和 Meta,以及一些其他大学联合完成的。这是同类项目中第一个大规模 AI 模型的公平性研究项目。
众所周知,AI 模型 / 人工智能模型现在非常流行,比如说在 Meta,AI 模型被 Meta 用来给用户做推荐,或者是提供个性化服务。从社会的角度来说,有必要知道这些 AI 模型在广泛使用过程中是否是公平的,还是说有偏见。所以现在问题在于如何进行 AI 模型公平性的判断呢?如何衡量它是否公平呢?尤其是为了评估 AI 模型是否公平,模型提供者的计算。
首先,需要基于用户信息所推演出来的结果,另外一方面又不能影响到用户信息的隐私性。所以,作为模型的提供者,Meta 是知道一个特定用户 ID 在 AI 模型中输入的输入值。但是,Meta 并不知道用户的敏感属性,比如说他们的性别。此外,用户也可以将他们有关于性别的敏感信息提供给某个调研。如何对 AI 模型的公平性进行评判呢?使用不同的指标进行衡量。
简单起见,给大家举一个非常简单的例子,将用户性别进行计算,比较一下平均推理的结果。通过计算平均推理结果,就可以知道 AI 模型到底是否是公平的。
以性别为指标,关键问题又变成了如何以保护隐私的方式来做对于 AI 模型公平性的衡量。在这样的情况下,模型提供者是知道用户推理结果的,但是他不知道用户的敏感属性。而调研人员知道用户的敏感属性,但是却不知道模型推理出来的结果是什么。
所以,要求我们做的是一方面需要计算最终的结果是否是公平的,利用来自不同数据源的数据进行计算。同时,确保用户的隐私始终得到保护。这就是我们一开始在和 Meta 合作时所设立的研究目标。开发的技术结合了不同的隐私计算技术,首先使用的是安全多方计算,调研者秘密在多个协助者之间分享用户的敏感属性,在我们的调研里,我提到有三家大学也加入了,他们就是在这个研究中的协助者。
模型的提供者 Meta 为用户的推理结果生成同态加密的结果,同时也提供零知识证明,证明加密推理的结果是正确的,并且是在一个范围之内。然后将同态加密的计算结果发送给调研人员、一协助者。一方面协助者拿到了调研人员关于用户属性的信息,另一方面又拿到了模型提供者的模型推演结果,所以协助者可以利用这些数据一道计算并且判断 AI 模型是否公平。协助者也用了差分隐私来添加噪声,从而进一步保护用户的数据隐私。最终通过计算之后得到的研究结论是可以以保护隐私的方式得到公平的计算结果。这是隐私计算技术在现实世界中第一次大规模部署,被用于对于 AI 模型公平性的衡量。
同时,也开发了新的开源平台,从而让去中心化的数据科学变得更加容易,因为我们希望能够弥合科学界、研究界、现实世界之间的鸿沟。这也是数据平台的起源,平台的名字叫做 CoLearn,它是一个新的开源平台,它使得协议可以在统一的框架中组合,并且构建一个经过精心设计的标准化、去中心化的编程抽象预设,它利用了最近在密码学和隐私保护方面的相关技术。
CoLearn 为去中心化数据科学提供统一的平台,从而将新协议的设计从设计到部署整个过程,不管是从时间的角度,还是对于部署人员精力的角度,都减少了几个数量级。从时间而言,之前一个月的工作,现在只需要仅仅几周就可以完成。开发人员也更容易利用已有的加密协议,帮助他们完成新协议的部署和设计。目前,CoLearn 也已经集成了许多应用于隐私保护、机器学习、联邦学习等最先进的加密协议。
当我们将隐私计算和区块链相结合,我们就可以实现一种新的资产,将其称为数据资产。区块链有助于提供用户数据使用政策的不可篡改数据,区块链也可以提供用户的数据到底是如何被使用的,通过隐私计算来保证,不仅仅是在处理过程中,同时也保证在计算过程中,以及在输入值、输出值方面都可以保证数据的隐私。将数据以及相关的策略封装在一起,从而创建了一些规范的标准,把它打包成资产,从而使得用户能够从自己的数据资产中获益,通过数据资产化,Oasis 可以打造新的负责任的数据经济,允许用户和企业在过程中从数据资产中获得价值。
比如说,已经用了基因组数据作为很好的例子,在实际过程中已经得到部署。因为用户的基因组数据可以说是最隐私的数据源之一,但同时它的价值也是非常高的。
用户经常会担心自己的基因数据到底被使用到哪里了呢?如果说他们将自己的数据提供给相关的数据分析服务,对 Oasis 来说,首次为用户提供了一个平台,帮助他们保证对于自己基因组数据的控制。与此同时,又可以将数据提供给其他方使用。在过程中,用户本身也能从自己的数据中获益,获得经济收入,同时保证了他们的数据隐私。
将不同的组件结合一起之后,社区就可以组成数据共同体,或者更进一步的数据 DAO 组织用于去中心化的数据科学研究。比如说数据的所有者和数据的产生者,可以用指定的策略对于数据集进行很好的管理。比如说,他们可以加入某些数据 DAO 组织,而这些数据 DAO 组织可以指定如何使用 DAO 中的数据,如何共享从数据中获得的经济收益。
而数据使用者、数据分析师可以搜索这些数据 DAO 组织,找到他们所需要的数据,然后在不同的数据集和数据源上编写自己的数据分析和机器学习程序、模型。数据分析的机器学习程序可以在分布式安全计算平台上运行,与此同时也保证程序是符合预期策略的。通过这样的方法,就可以减少数据使用的摩擦,消除数据孤岛,并且实施更强大的安全和隐私保护。
我坚定不移地相信,在十年后,数据信托、数据共享将会成为使用数据源的主要方式,实现所有者经济,使得用户作为数据的所有者、数据的合作伙伴,从数据中获得经济收益。在十年后,新形势的数据信托和数据 DAO 组织将创造巨大的经济价值,比当前要高出几个数量级。
总而言之,通过从 Web2 中心化的控制,转变成 Web3 的去中心化控制,我们可以帮助用户控制对于数据的使用,而无需依赖任何中心化的第三方。通过这样的范式转变,就可以真正走向负责任的数据经济。对于互联网的未来,也必须建立负责任的数据经济。
2020 到 2030 的十年,就是建立负责任数据经济的十年,感谢各位的聆听!
《数字时代的自我修养》——海南君顾数科研究院创始人兼院长单福
大家好!非常荣幸有机会参加 2022 区块链上海国际周,我是君顾数科的单福。
君顾数科主要是研究传统金融行业的相关政策和相关动态,更多的是站在金融消费者、投资者角度来看待和研究各种金融政策和现象。
今天,我分享的题目是《数字时代的自我修养》。之所以提出这个命题,是因为我深刻地感受到人类正从物理世界向数字世界逐渐转型,非常有必要对数字世界中的相关命题进行各种研究。尤其是对于普罗大众应当以什么样的心态去认识数字世界,怎样才能更好地在数字世界里获得更有尊严的生活,这可能是大多数人需要考虑的话题。希望今天的分享,能够抛砖引玉,引出大家更多更精彩、更专业的观点。
今天的分享一共分四部分:
- 第一部分,人类已经迈入数字世界。
- 第二部分,何为美好数字世界。
- 第三部分,数字时代的自我修养。
- 第四部分,用户控制的数字身份和数据账户体系。
一、人类已经迈入数字时代
研究人类历史的角度非常多元的,既可以从生产力的发展角度,也可以从生产关系,甚至从宗教等各方面来看。我的角度是从人类掌握数据、以及分析数据的能力和水平出发。我认为,人类的发展历史,就是一个不断深入理解数据、从数据中提取智慧,以更好地改造社会、创造美好生活的过程。由此可以说,人类对数字收集的广泛程度和深度、利用数字的专业程度等等,都是判断社会技术先进程度的重要标准。为此,人类社会的发展可以分为以下五个阶段:
最漫长的、持续了几万年的是第一个阶段,人类数据一直没有被收集或者没有被大规模收集。从上世纪 40、50 年代开始进入第二个阶段,大型计算机被发明,这些计算机设备首先被用在国防等相关领域进行分析、处理、计算。第三阶段的特征是计算机设备从国防和大型工业领域、大型工业企业下沉到个人,个人的数据开始被收集、分析和使用。第四个阶段,随着互联网的出现,个人电脑也进行了联网,由此带来人的数据也被联网收集和初步分析使用。第五个阶段是人类数据被联网大规模收集和使用,这是当前所处的阶段。
从中不难看出人类社会发展是加速式的发展,第一阶段持续了几万年,但后面几个阶段到现在只持续了不到一百年的时间,这也是我们感受到社会在跨越式发展和变革的重要原因。
未来也许会出现更加高科技的数据收集方式,包括现在探索中的脑联网等技术,由此不难得出一个结论,人类的衣食住行等物理需求必须要在物理世界得到满足,但是人类的喜怒哀乐、社交等情感需求,可以、甚至可以更多地在数字世界得到满足。物理世界对人类需求的满足是存在上限的,但是数字世界给人类情感精神带来的满足不存在上限,因此数字世界创作的产出可以超过线下的物理世界。
二、何为美好数字社会
首先,我想提出一个对社会运行模型的简单框架。任何社会运行的基础模型就是满足人的需求。区别在于,它满足的是少数人的需求还是大部分人的需求,以及它满足的是物质需求为主,还是精神需求为主?第二,这些需求由谁来满足?比如说封建时代很多生存需求是自给自足的,也就是自己满足自己的衣食住行等需求,精神需求也在自己的社交过程中自己解决。工业化时代的特点是社会化大分工、大生产,衣食住行可能都来自不同的工业企业。数字时代的特点跟工业时代不一样,它具备非常典型的「赢者通吃」的规则。也就是说,可能到最后,为我们提供数字化服务的,只有少数几家平台企业,这少数几家平台企业就能较好地满足人类的物质需求和精神需求。
这也就引出了社会运行过程中的公平、效率、风险的三角均衡的考虑。对普通民众而言,在不同时候有不同的诉求,战争和和平年代的诉求存在明细差别。现阶段大家基本已经解决温饱,对公平的呼声会比以前高。对于生产企业,他们关注的是效率,因为这直接决定了他们的竞争力和盈利能力。对于政府监管部门而言,他们比较看重中间的风险因素,既包括实体风险,也包括金融风险等等。
在此,我想把古人所畅想的美好社会跟大家再温习一下。在《礼记·礼运·大同篇》里提到:大同社会是大道之行,天下为公,选贤与能,讲信修睦。故人不独亲其亲,不独子其子等。从中不难看出,他们所畅想的理想社会,即便放在现在也不落伍,理想社会更重要的是反映人和人之间的关系,人的尊严和人的精神面貌是不是积极向上,是不是平等友爱的关系,并不太在乎他的生活水平是不是特别满足富裕。话说回来,如果能够达到这个理想社会,那么在任何一个时代,这个国度的生产力水平一定能够取得当时技术条件限制下最高水准。
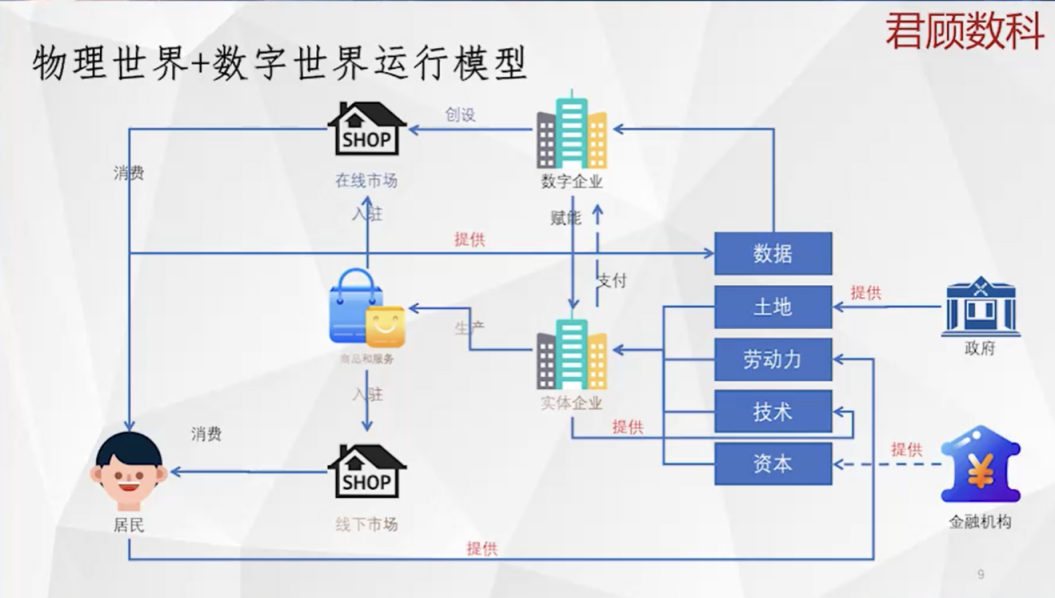
物理世界 + 数字世界运行模型
我试图想把物理世界和数字世界的运行基础逻辑给简要说清楚。(如图所示)左下角是居民,一方面居民要消费,另一方面要参与生产。消费的钱是生产得来的,是向实体企业提供自己劳动力以后的劳动报酬来获得货币的。实体企业通过居民获得的劳动力,加上通过政府获得的土地,通过相关渠道获得技术资本,通过金融机构获得金融资本等。有了这些传统的生产要素,加总在一起就可以生产出很多的商品和服务,这些商品和服务能够满足人的很多需求,因此也产生利润获得回报。
数字企业的运行模式跟物理世界不太一样,它以数据为生产原料,那数据是怎么来的呢?这些数字企业成立一个平台,在平台里设立很多生活场景,这些生活场景能够给人们生活的衣食住行各方面带来很大的便利。所以它通过这些便利吸引和积累了很多用户,又在用户活动过程中积累了很多用户的个人信息和行为数据。因此,能够基于数据更好地刻画人的特征和需求,因此它能够更好地指导和优化产品的生产设计等相关过程,从而给实体企业生产带来效率和效益上的提升,这反映了数字企业和传统企业相生相伴的关系。
数字企业在运行数字经济时产生很多数据。从层级来讲,分为基层数据和高层数据。基层数据就是原始数据或者明细数据,高层数据是基于基层数据的分析、归纳、统计等得到的数据。基础数据分为对物理世界观察的基础数据和对人类行为的记录数据。人类行为的数据包含个人信息或者未脱敏的数据,以及不包含个人信息的数据。重点说一下未脱敏的原始数据,这也是当前 Web2.0、Web3.0 里大家争议比较多、矛盾比较多的地方。
我认为,一个比较美好的数字世界应当是这样的。数据的产生、收集、利用、协同全流程都是相对完美的状态。比如数据的产生:用户能够以相对低的成本获得相关的数字设备,用户行为数字化比例非常高。数据的收集:相关企业都能够征得用户的实质知情同意,数据的来源是光明正大的。数据的利用:算力极大丰富,由此能够深刻地揭示社会的运行规律,为用户提供更加优质的产品和服务。数据的协同:凡是对数据有需求的企业,都可以以相对合理的成本获得他们所需要的数据,并且不会存在来源不稳定的后顾之忧。能够想象到,整个社会将是需求收集精准、生产高效、风险可控,物质文明和精神文明非常丰富的社会,这是我对美好数字社会的畅想。
与之相对的是丑陋的数字社会,相信大家在很多科幻片里都有见到过,高科技 + 低生活同时存在,很多数字企业把用户当做它的「原料」来对待,用户通过出卖自己的劳动和数据才能获得必须生活物资。他难以逃离这个社会,因为离开后就无法很好地独立生存。并且数据被少数企业所垄断,其他组织基本没有可能获得相关数据,也就难以和这些企业进行正常的市场竞争。并且物理世界相关的生产组织,以及用户的需求都被这些数字企业所控制、引导和垄断。相关的监管部门缺位、甚至被俘获,整个社会处于阶层固化、毫无生机的状态,在我眼里这是一个丑陋的数字时代。
我个人觉得当前的数字时代既没有那么美好,也没那么丑陋,而是处于相对中间的位置。现在大部分人都处于 Web2.0 时代,Web2.0 时代大家通常做法是怎样的?每个人都有若干个账户或者是数字身份,通过某个账户进入到某一个平台企业的某一个场景,比如说电商、出行、资讯阅读等等,在这个场景里获得了便利,同时也将它自身的个人数据交给平台方,平台方存储在自己私有的数据库里。整个过程中,数据是从个人流向平台方,并且其他方想要获得这些数据非常难,要么价格特别高,或者是通过灰产、爬虫等偏门的方式来获得。这离理想的数字社会尚有不少距离。
三、数字时代的自我修养
我认为,任何时代都需要有与之配套的生存素养。比如说在原始时代的时候,要有相关的打猎技巧才能捕捉到足够的食物,才能养活我们自己和族人。同样封建社会要学会种地,或者是织麻纺丝之类的,工业时代要学会炼钢制造设备。同样,数字时代的居民也需要有一些素养要求,我从以下几部分阐述:
1)理念部分
因为梅特卡夫定律,互联网平台对个人数据的渴求是没有边界的,它背后需要不断地扩充自己的场景和用户规模,以使自己对竞争者始终保持领先地位,否则就会逆水行舟,不进则退。所以他们尽可能地发掘更多的场景、吸引更多的用户、收集更多的数据。
普通参与者在这里具有多重身份。第一,他们是消费者;第二,他们是数字时代相关生产数据原料来源。数字企业、平台企业和用户是存在利益冲突的,因为个人数据主要来自于用户。在有利益冲突的情况下,需要我们的监管部门能够秉持公允客观的立场,和与之配套的技术水准,来进行市场秩序的维护。
2)目标部分
我们的目标是什么呢?在数字时代,如果你技术水平比较高,可以兼济天下,帮助大家做有尊严的数字居民。如果只是普通居民的话,那就是独善其身,做一个有尊严的数字居民,有尊严的核心是我的数据我自己能做主。我的数据在没有得到我许可的情况下任何人都拿不到。数据给对方之后,对方必须要安全保管。另外,对方虽然掌握我的很多个人数据,但对于那些我不希望被别人知道的隐私部分,即便他有这个技术水平,也不要尝试去猜。我的数据现在在这儿,但是我需要给别人的时候你也需要来配合。如果数字时代居民能有这样的权利和地位的话,可以认为这样的数字生活是比较有尊严的数字生活,居民也是比较有尊严的数字居民。
3)路径部分
如何达到这样的途径?
- 第一种,数字企业和互联网企业特别有良心、有道德,是存在这种可能的。
- 第二种,有赖于监管部门的公正以高效,即便在我们的权益被侵犯的时候,监管部门能帮我们发声,维护我们的正当利益。
- 第三种,依靠我们自己,提高自身的数字化素养,将自己的数字安全和数字尊严主要肩负在自己的身上。
这里面会类似存在最佳实践的概念,要做的不是一个具体的事,而是持续的事。首先要了解当前自身产生了哪些数据,哪些有被收集、被计算、被画像、被协同了?在这个过程中,又存在哪些侵犯我权益、损害我尊严的地方。有的话,就查漏补缺、亡羊补牢,并且把整个过程内置于后续的循环周期中去,使自己的个人数据始终处于自我掌控状态,这里的自我掌控,是指数据要么没有被别人掌握,或者是经我我许可授权后被别人掌握的相对公平的状态。
当前个人数据被收集,依托于相关的硬件、软件、网络设备等。硬件更多是手机、个人电脑、智能家居、穿戴设备等等。采集的信息包括基本信息、行为数据、生物信息(指纹、人脸、声波纹)、行为规律等,行为规律包括这个人经常在几点上网,几点聊天,打字频率等等。这些环节都是可以成为泄露个人信息的环节,也是可以改进自身数据安全和数据尊严的环节。最核心的是要建立为用户所掌控的数字身份,这可能是实现用户数字主权和有尊严数字生活的必由之路。
四、用户自主掌控的数字身份和数据账户体系设计
用户控制的数字身份和数字账户体系最大的特点是「用户控制」。也就是说,当前也有很多数字身份、数字账户,但它不是被用户控制的,这在 Web2.0 里非常明显。为什么要控制权呢?当前数据的所有权在学界、业界关系并不是很清晰,并没有很明确的说法。在此情况下,控制权可能是最核心的一个权利,数据归谁控制,很大程度上决定了数字生活的质量和人的尊严。如果数据是被用户所控制,那将大大减少用户个人数据被泄露,个人隐私被泄露,个人尊严被侵犯等情况,如果数据是被平台或厂商控制,那么我们基本上没有太多自主空间,只能依赖对方的道德血液,或者监管部门的公允专业。从用户角度看,个人数据的控制权要尽可能多地从平台企业回到用户这。只要只有用户对自己的数据有控制权,他才有底气说我能够维护好自己的数字尊严。基于这个理念,我设计了如下的数字身份体系和数据帐户体系,他能够较好的保护用户的数字权益,同时能够兼容 web2.0 和 3.0。
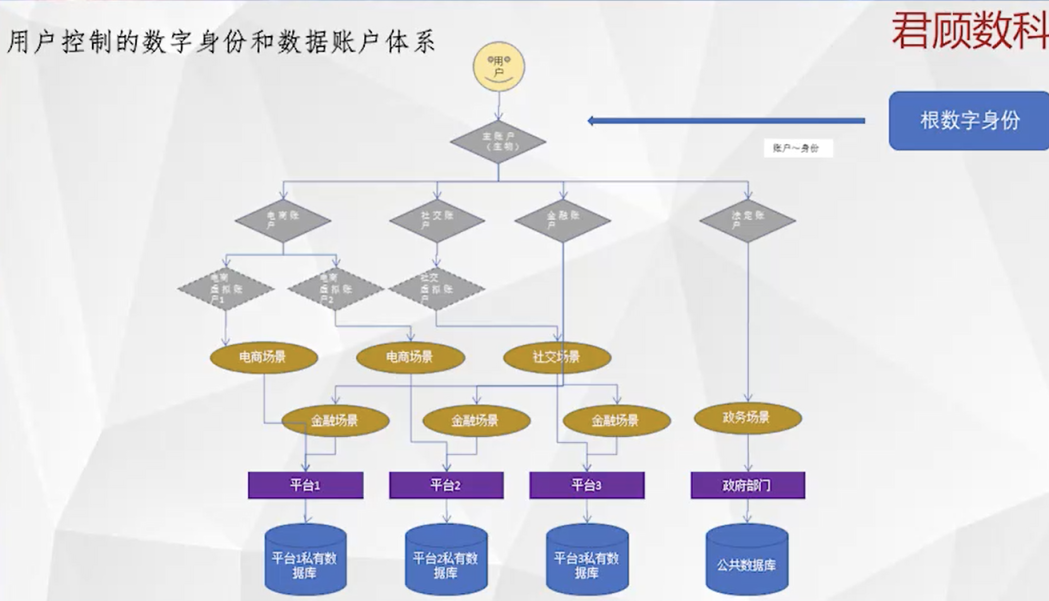
用户控制的数字身份和数据账户体系
从上往下看,最上面是用户,用户下有一个主账户,主账户是由用户的生物信息来控制的,比如虹膜、指纹、声波纹、行为特征等等。主账户下分别是子账户和孙子账户,一个主账户可以控制若干个子账户,一个子账户可以控制若干个孙子账户。这里的控制是单向的,即主账户可以推导出多个子账户,子账户可以推导出多个孙子账户,但你不可能从某一个孙子账户推导出它属于哪个子账户,更不可能推导出他的根账户身份。
为什么要有这么多账户呢?因为用户的需求是多元的,每种需求所需的个人信息也存在较大差别,因此需要用不同的账户来适用于不同的需求场景。我的建议是用户按照需求的目的、时间、空间进行切分,形成多级多类账户。比如说我按照我的目的把数字账户定义成多个子账户,包括出行专用的子账户、电商专用的子账户、社交专用的子账户、资讯阅读专用的子账户等等,每个子账户上都存储有此类需求所需的个人信息,比如电商子账户里存有我的收货地址和手机号,出行子账户存有我的公司和家里地址等。
子账户之下,是各级孙子帐户,孙子账户可以根据平台和时间进行切分。以电商为例,可能很多人既用京东,也用淘宝、拼多多。那么就可以在电商子账户下建立京东电商孙子帐户、淘宝电商孙子帐户、拼多多电商孙子帐户,这三个孙子帐户共享电商子账户上的个人信息,即收货地址和手机号,当在京东购物时,就使用京东电商孙子帐户,以此类推,这是在空间(不同平台)上的切分。孙子帐户下还可以建立玄孙帐户,我建议可以在时间上进行切分,比如=可以把我今年在京东上的账户独立为一个玄孙账户,到明年又新建一个玄孙账户来使用,这两个玄孙帐户都由京东电商孙子帐户来衍生和控制。
这样相对于每一个具体的账户,都有特定适用的时间、空间、平台、场景,都是非常聚焦的,因此其使用期限能够非常短。这样即便某个孙子帐户的个人数据被不合理的收集,那么他也只能收集用户很小一段个人信息,且一旦被用户发现,用户能迅速作废这个帐户,同时新建新的帐户参与对应的场景,同时平台企业要想对不同帐户进行关联和计算,难度会比以前大很多,在用户不授权的情况下,平台很难单方面对用户进行画像。对用户而言,帐户虽多,但都是分层的,上层衍生和控制下层帐户,最上层的是根账户,能够控制所有帐户,用户只需要管理好这个根帐户,能够用多个子账户、和孙子帐户进入数字世界,具体使用哪个身份,完全由用户自己说了算,用户甚至可以用一个身份浏览商品,用另一个身份下单。这样的数字身份体系,除了用户控制,用户说了算,用户还能够通过《个人信息保护法》等相关法律,把用户之前在平台上积累的数据拷贝或者迁移到自己所控制的账户上,形成真正属于自己或被自己掌控的数字身份和数据账户体系。
上述设计的关键在于根账户由谁来建立、谁来运营、谁来管理。大概分两种情况:第一种,用户为自己建立和自主管理,这是很多 Web3.0 项目的做法,此次的主题是数字身份,有很多专门的介绍,在此我不再赘述。第二种,在 Web2.0 的逻辑之上,由一个独立公允客观的第三方为大家建立。这里需要说一下我们的邻居印度,印度为 13 亿居民建立了一个叫 Aadhaar 的帐户体系,并基于该帐户体系,做了很多上层应用,比如他们的账户聚合平台,是一个为个人集中管理自己金融数据的平台。该平台由印度央行监管的一个非营利的机构运营,把居民分散在多个金融机构中本人的金融数据进行统一的管理。用户在账户聚合平台上可以查看和管理他在多家机构上的所有金融数据。这里的管理包括知晓、提出反对意见和对外协同等。这里的协同是指,如果有哪家企业需要我的金融数据,他可以在账户聚合平台上向我提出申请,我同意之后,它就能获得我在多家金融机构上的金融数据。这种做法充分尊重用户的数据权益和隐私,对有数据需求企业而言,帐户聚合平台是他们非常好的数据协同窗口和方式。
值得注意的是,上述数字身份和数据帐户体系的设计中,根账户只有一个,且只被用户自身所掌控,我们平时用的比较多的法定身份,或者法定数字身份,是其中一个特殊的子账户。另外我们也可以建立能够在若干家企业、若干个平台中通用的联盟性质的数字子帐户,当然也可以是只在某家企业、某个 APP 上使用的场景化数字子帐户。即用户可以根据其需要,以子账户或孙子帐户的方式来自主建立和使用数字身份,这里的重点是用户自主可控,且都归用户的根账户所管理和控制。这是我提出的、更多由用户而非他人来控制的数字身份和数字账户的体系,供大家参考。
这里同样存在公平、效率、风险权衡的问题。在 Web2.0 时代,效率是很高的,但是效率是单个企业的效率,如果把范围扩展到多个企业、整个市场的话,效率并不高,因为数据的协同非常低效。公平而言,见仁见智,我个人觉得在 Web2.0 时代有很多对用户不够尊重,没经用户允许就收集用户隐私的行为,这对用户的尊严而言毫无疑问是挑战,自然也谈不上公平。风险而言,由于底层数据有很多来路不正,自然潜藏着很多争议和风险。
在上述用户自主管控的数字身份和个人账户假定能实行的话,风险会比较低,公平也能保障的比较好。风险之所以低,是因为数据是分布式的,不至于一个人的数据泄露会导致很多人的数据泄露,不存在全员性和系统性风险。公平的话,由于都是你自己来管理,对外授权肯定也是自己授权的,自己说的话要算数,不应该的授权自己也需要为此承担责任,因此基本就不存在不公平的情况。三者中欠缺的是效率,因为每个人的数字化素养千差万别,更多人的数字化素养都是相对低的,因此效率的提示有赖于非常多的数据专业机构、中介机构,为用户、为市场提供公允和专业的数据服务,才能有效地提升效率。
对于当前仍然处于 Web2.0 时代的很多用户而言,我个人建议多考虑使用加密算法来有效提升和改进自己的数据权益。比如说对于涉及较多个人数据管理的服务,尽可能从公有服务转为私有服务。比如大家很多数据都存在网盘上,存在数据丢失或罚没的情况,这里建议有专业性、有财力的居民可以考虑建立个人的 NAS 存储系统。还有一些将自己的密码托管在「别人家」的,也可以考虑把自己的密码置于自己的管控范围内,通过个人密码管理器来实现。
对于一个中心节点向多人提供服务的情景,用户应尽可能选择用户掌控密钥、或用户自主加密的技术,这里的自主加密是指独立于厂商之外的用户自主加密。比如说邮件发送,你发送给对方的现在是明文,未来可以是密文,密文是由用户自己的密钥来加密的,邮件发出之后别人收到的是密文,但可以用发送方,也就是用户的公钥来解密,当然还有签名等过程,这样可以有效地杜绝未经授权的人来获取到你的邮件和相关情况,因为过去的确发生过邮件服务提供方通过读取用户的邮件来获得商业秘密的情况,且被美国法院判罚。再比如社交聊天中,我发送的是未经用户自主加密的明文文本,对方接受的也是这个。我相信聊天软件运营方在中间是有加密、解密的过程,但这不是用户自主的。用户自主是什么呢?用户发送给对方的是用用户私钥加密之后的文本,接受方接受之后,由于是用户信任的对方,因此可以获得用户的许可,对密文进行解密,从而阅读到明文,中间不会有任何第三方,包括聊天服务提供方,获得二者之间的聊天内容。这样能够确保两人之间的通讯只有这两个人才知道。国外已经有类似的项目出现,并且在主流社交媒体上也有很多的用户了。但国内相对来比较少,这也反映了国内的理念和生态,跟国外还是存在一些差距的。
以上是今天我给大家带来的分享。关于数字时代的发展趋势,美好数字生活的判断标准,当前的现状以及未来如何有尊严地在数字世界里的看法,并提出了如何通过用户管控的数字身份和数字账户体系,以更好地维护用户权益。不成熟看法,欢迎一起交流和探讨。
我的分享到这儿,谢谢大家!
圆桌讨论:《区块链安全及隐私》
Blue,慢雾首席技术官
郭宇,安比实验室创始人兼首席执行官
Emre Tekisalp,O(1) Labs 首席执行官
Harry Halpin,Nym Technologies 首席执行官
Blue(主持人):今天圆桌的主题就是「区块链数据安全与隐私」,话不多说,直接开始。
先请各位圆桌嘉宾简单介绍一下自己和您所在的团队,请 Harry 先介绍。
Harry Halpin:大家好我是 Harry Halpin,我是 Nym Technologies 的首席执行官,也是联合创始人。Nym Technologies 是一个隐私的混合网络 0 层解决方案,有点像去中心化的 VPN。今年年初的时候在 Coinlist 上做了区别中心化募资,同时也得到了 Banners、(音)ASE(音)的投资支持,今天非常高兴能够和各位参与到圆桌论坛。
2019 年的时候我自己也来过上海,所以今天也觉得特别高兴。
Blue(主持人):请 Emre 跟我们介绍一下你自己。
Emre Tekisalp:我的名字是 Emre,我是 O(1) Labs 的首席执行官,具体做的是基于零知识证明的技术和区块链。孵化了 Mina(音)协议,这是大概在 2021 年之前所上线的一层协议,现在正在上面部署零知识证明应用,从而延续开发者后续可以开发通用型智能合约。现在也有名为 Snark GS(音)的新 SDK,从而允许开发者可以基于零知识证明来写 TypeScript 类的应用程序。
Blue(主持人):请郭宇介绍一下您自己。
郭宇:大家好!我的名字是郭宇,我是安比实验室创始人兼首席执行官。安比实验室专注于智能合约和零知识证明,同时也帮助其他团队构建去中心化的工具库和应用。现在也在开发使用零知识证明进行数据公平交换的去中心化协议。
Blue(主持人):我也介绍一下我自己,我是慢雾的 CTO,我的名字叫 Blue。慢雾是由拥有十年以上的网络安全经验团队创立的,目标就是让区块链系统尽可能地安全。
现在正式开始圆桌讨论吧,先问第一个问题,有一些区块链将隐私作为一种可选的功能,比如说在以太坊上看到 AS Cash(音)项目就是将隐私作为可选功能。也有一些区块链,比如说像 Z-cash 将隐私作为默认的功能。但是区块链真的是隐私的吗?请各位回答这个问题,请 Harry 先回答。
Harry Halpin:我快速回答一下这个问题,我的观点是隐私代表的是整个系统的总体属性,很多人对于零知识证明非常感兴趣,尤其是将零知识证明应用在以太坊的扩容方面,他们认为零知识证明可以提供链上隐私,也就是说在区块链上的数据就可以保证隐私性。比如说,Tor node cache(音)最近刚刚关闭的 mixer,也是他们的混合池匿名池,做的就是这一点。但事实上,当你和区块链系统进行通信的时候,你会用到点对点的广告,也就是说你的交易时间,你的 IP 地址,至少可以把你定位到一个城市。如果说没有办法定位到你具体所在小区的话,可以把你定位到城市,这些信息都是公开的。
虽然零知识证明取得了很多进展,但是它们还不够,需要其他的技术。比如说在底层需要混合网络、匿名池,各种洋葱路由,以及更高层的隐私增强智能合约技术,才能真正实现在区块链和 Web3 上的隐私性。
Emre Tekisalp:不管在区块链上做的隐私是什么,这些隐私往往只和 Token 本身的转移有关,我也并不觉得这件事情令人惊奇,因为大部分 Web3 还是和 Token 交易、NFT 交易有关,还没有做交易投资之外的应用程序。原因也很简单,零知识证明技术本身就很难,现在看到很多零知识证明的项目都还在研发之中。另外一个更重要的原因是如果你看一下 AS Cash(音),或者是其他基于以太坊的二层项目,有一些声称自己能够做到隐私保护,但实际上这样的说法并不完全属实,因为数据会被发送到零知识证明的计算中心,或者是某个云厂商,由他们代表用户生成证明。这是因为本身零知识证明从计算上对算力的要求高,而且计算非常昂贵,所以对于用户来说,需要降低零知识证明计算的成本,从而使得它能够适配普通的用户设备,这点非常重要,也正是在 O(1) Labs 上正在开发的业务。
现在已经几乎准备好上线了,我们的技术允许普通用户在自己的个人笔记本电脑、智能手机上生成用于通用性计算的 ZK 证明。不管是做任何类型的数据证明,不管是计算还是提供证明本身,都允许用户在自己的设备端生成,然后将相应的证明发送到区块链,这样区块链接收到了证明,但是却没有办法判断,或者没有办法探查到用户设备侧到底进行了怎样的及钻。
郭宇:我觉得不管是 Z-cash 还是以太坊的其他加密,比如说 AS Cash(音)或者 Tornado Cash,这些都还没有办法做到完全隐私。因为我觉得,在一定程度上区块链账户本身并不是默认隐私保护的,也就是说对于用户来说,最开始大家有的只是一个普通的账户,之后可能变成了某种程度的隐私保护账户。也就是说,隐私的超过取决于匿名级的大小。就我的角度来看,我不认为很多人会愿意进入到匿名池。也就是说,匿名池不会足够大,也就导致了隐私保护程度相对来说比较弱,这也是为什么 Tornado Cash 这样的项目需要推出一些激励措施,鼓励更多人将自己的资产存入到匿名池、混合网络之中。但是通过激励来做隐私保护,其实并不是那么容易实现的,尤其是在隐私保护方面。
所以我认为,主要的挑战是要如何扩大匿名池的大小,从而帮助那些真正关心关注隐私的人。这就是我的看法。
Blue(主持人):接下来一个问题有关于安全,哪怕说区块链本身是安全的,但是在底层区块链依赖于互联网,所以我们怎么知道你的互联网连接是不是安全的呢?请 Harry Halpin 先回答。
Harry Halpin:我的答案是对于最终的用户来说,几乎不可能知道你的互联网连接是否安全,所以作为隐私方面的专家,作为隐私技术方面的公司,Web3 的初创企业,我们做的一件事情是需要同时确保区块链更加安全,有各种各样的共识算法、零知识证明、加密学,比如说像 Nym 用的混合网络将数据包混合,并且伪装,从而无法判断谁将数据包发送给了谁。
但另外一方面,我们也需要为用户提供一些他们可以识别、可以理解的信号,比如说一个红色的按钮变成了绿色按钮,这就是我们在几周之前推出的功能。通过这样的方式,用户至少可以通过查看信号去判断连接到区块链互联网连接是否是安全的。目前不管是 MetaMask 还是 Infura 还是其他的基础设施,都没有这样的功能。
Emre Tekisalp:刚刚 Harry 所介绍的这种技术,我觉得非常重要,我也想要就这个问题再提另外一个维度的信息,也就是用户可以在自己的设备上连接区块链。灵活度越高,他们能够获得的隐私保证就越强。其中一部分在你的设备上运行全节点,不管是在 Tornado Cash,还是一些更早期的项目,大家都是通过钱包来连接这些应用程序,而这些钱包也连接到其他的全节点。也就是说,钱包有很多有关于用户的信息,因为您将信息发送给了这些钱包,但同时钱包也能够判断感知到你对于各种应用程序的访问,可以感知到交易全节点的情况,这是我们都希望看到的。
由于非常昂贵,所以很多用户很难在自己的设备上运行全节点的,这也是我们通过 Mina 协议希望为用户提供的,因为 Mina 的核心前提是所谓的同步区块链,整个区块链能够始终保持固定大小的零知识证明,能够提供证明,这个证明的大小是固定的,而且足够小。从而使得普通用户哪怕使用普通的智能手机或者电脑,就可以下载几 GB 的数据,你可以自己验证我发给区块链的实例是真实的,没有被任何篡改,没有被攻击,我也可以尝试发送一笔交易,通过我之前的确认可以信任交易、账户余额等其他信息,通过这样的方式更好地实现隐私。
郭宇:这是一个非常好的问题,我认为整个互联网的基础设施是不安全的,先回顾历史,我认为 ICP 协议初始的设计思想,很多协议都没有考虑到安全性,也就是说它们并不是所谓的拜占庭容错的。假设 99% 的用户都是好人,但是我们今天面临各种各样的垃圾邮件,也面临各种各样的攻击,比如说像日食攻击,还有一些其他 DNS 的服务器,可能也会成为攻击点。所以我认为,要从头开始重建互联网协议,或者说形成以区块链为中心的新型互联网。从这个角度来说,需要的时间比我们预期的要长。
我还担心另外一件事情,最近我手机的浏览器一直在提醒我,我希望访问的某些网站是有风险的,但是我对于网站是否有风险一无所知,我也不确定网站是不是真的有风险,还是说只是因为本身浏览器的原因就是要发风险提示。对我来说,我真正访问这个网站之前,需要进行大量研究、大量调研。
这个问题非常好,区块链更下层的互联网连接并不是那么安全,这也是我非常担心的一点。
Blue(主持人):接下来的问题问 Emre ,ZK 技术是被视为以太坊可扩展性的主要挑战者,所以我想请问 ZK cash(音)到底有什么用?对 Web3 以及科技世界有多么重要?
Emre Tekisalp:这是一个很基础的技术,有很多使用场景,其中有一些我们还没有解锁。如果我们后退一步,思考一下对于用户来说 ZK 技术零知识证明到底是什么呢?它实际上属于密码学的分支,允许你证明计算结果的有效性,所以对于很多其他类型加密。比如说公私钥加密,对于这样类型的加密学,当你签署签名的时候,基本就能证明数据的所有权。
但是在零知识证明中,你可以证明计算已经正确完成,但是你却没有必要披露到底谁发送了信息,计算的输入值到底是什么。因此零知识证明提供的是一种全新的能力,所有的计算都是由中心化设备在云上完成的。对于这样的世界来说,零知识证明技术变得更加重要,这也是为什么零知识证明技术和我之前提到的 Web2 世界能够有挑战的力量,同时对于区块链来说也非常重要,因为它能够让所有权回归给用户。
您刚刚也提到了,围绕着 ZK 零知识证明技术有很多探讨,将其称为可扩展性的挑战者,但是细节我就不多加赘述。本质上,ZK 技术就是为区块链提供更多的吞吐量,而不需要牺牲去中心化。除此之外,隐私,尤其是数据隐私是另外一个非常重要的领域,我在这个领域已经有很长的工作时间了,所以我们总是看到各种各样的新发明,认为可以解决各种各样的挑战,从而使得数亿用户使用加密技术,不仅仅只是将它用来作为资产的交易。
可扩展性是下一件亟待解决的事情,现在是否有可扩展性呢?在一定程度上有,因为很多区块链的 TPS 不断提升,但是我们又面临着另外一个区块链广泛采用的问题。对用户数据进行隐私处理将会是下一个巨大的推动力量。因为如果你想要看一下各种各样的 DeFi、SocialFi、NFT 等等,目前你要参与这些应用的话,必须要有大量的资金投入,必须要购买 NFT,或者说必须要购买 NFT 从而加入某个 DAO 组织,意味着先期必须要有几万美元的投入,这就变成了大型机构或者富有科技界人士的「玩具」,但是我们需要有更普通的应用程序,可以让普通人所使用。
比如说在普通的世界中,程序允许普通人申请贷款,不需要抵押,或者在提供担保比较低的情况下就可以获得贷款。用户也应该使用这样的应用程序,证明他们属于某个群体。比如说是某个国家的公民,属于某个公司,或者在某家大学上学等等。这些应用当前都是不可为我们所访问的,因为大家不敢把这样的信息放在区块链上,一旦放在区块链上,它就会永远公开,任何人都可以看到,就像是你今天自己不会去分享你的地址一样。大家通过在区块链上查看,可以看到你之前的交易、之前的转账,对有些人来说这样的信息是可以公开的,但是很多有价值的现实生活信息不会愿意放在区块链上,比如说个人的信用评分,自己的工作薪水是多少,毕业于哪所学校等等。
为了让普通用户获得更多有用的应用,也需要这样的信息能够被放在链上,这也是为什么隐私对于用户的大规模采用非常重要。我们认为零知识证明使得我们可以将这些类型的信息、数据、技术、计算上链的核心技术。这样就可以拥有通用的 Web3 应用程序,你的父母、你的朋友,他们虽然对于加密技术不关心,但是他们也可以使用这样的应用程序,因为其中有很多创新,有一些更公平的方式。所以我觉得隐私确实对行业非常重要。
Blue(主持人):非常感谢 Emre ,接下来一个问题想问 Harry ,区块链技术如何帮助互联网传统公司变得更加安全呢?
Harry Halpin:我想就 Emre 刚刚介绍的再补充几点,我们有全新的基础技术,这些技术非常棒,有很多 Web3 应用。但反观一下,过去几年在区块链技术正式起飞之前,在互联网世界到底发生了什么?有斯诺登事件,斯诺登事件告诉我们美国政府对于互联网交易中的大部分业务会进行监视,并且对相关的数据进行记录,记录互联网数据成本非常低。同时也可以利用机器学习、人工智能对这些数据进行分析,这是美国政府对于公民个人自由的侵犯,很多人对于美国政府的做法不满。
现在除了政府之外,对于小型参与者来说,对互联网流量进行大规模监控也变得更加容易。这个问题不仅仅影响到了 Web3,同时也影响到了在互联网上所有参与者,影响到了传统政府。比如说 Nym 项目得到了欧委会的支持,当前也聘请了厄瓜多尔前银行行长,他主要致力于隐私保护的 CBDC。另外这也影响到了整个世界,影响到了像苹果、Google 那些传统公司,现在这些公司希望能够增强隐私。至少对于 Google 来说,因为他们的商业模式进行大规模网络活动的监控,同时也依赖于广告,所以 Google 是存在隐私问题的。
在传统的硅谷互联网世界里,很少有人对于这一点投入研究。对于政府来说,更多是利用这项技术。所以,坦率说,Web3 将会产生隐私技术,不仅仅能够为用户使用,同时也能为政府、企业、机构所使用,将通过标准组织,比如说像互联网工程任务组一道构建互联网协议的基础,我们也在中间做了贡献,就是混合数据包格式。
Blue(主持人):谢谢 Harry,最后一个问题想问郭宇。Web3 旨在保护用户的数据,但是数据经常在链下存储的,主要是因为链上存储的成本非常高。所以想请问,有没有比较好的方法,在保护隐私的同时,能够向区块链发送数据?
郭宇:一般来说,需要有两个关键的工具,一个是所谓的链上数据 Ankr 数据锚,另外一个就是高效的 ZK 证明,对于链下数据能够进行验证和证明,链上数据「锚」可以是一段数据的 SHA-256 哈希,也可以是加密承诺。比如说 KZG10 承诺。但是对于一个巨大的数据文件,或者是数据库、数据集而言,也许我们需要带有知识证明的 MerkleTree 或者是更加高级的 Verkle Tree,这个数据锚必须要足够小,这样的话你就可以实现低成本的上链。另一方面,它必须要和原始数据绑定,绑定的意思就是说如果链下原始数据更新,链上项目的承诺也会发生变更。但是链上的承诺,链上的数据锚也应当要隐藏原始数据的相关信息。
另外一个技术就是 zkSNARK,zkSNARK 可以保证链上 Ankr 数据锚的安全性、可靠性。另外,zkSNARK 也可以使用链下的数据,以保护隐私的方式来使用。我现在在这里谈到的是通用型的框架,可以将大量数据锚放在链上,而我们可以在链下进行数据的处理和数据的操作。这样一来,不管链下的数据有多大,我们都可以做到。
然而要实现这一点,毋庸置疑还面临许多挑战。
第一大挑战,链下数据经常变化更新,所以我们必须要发明一些全新的东西,用全新的技术,实现对于链上数据锚的低成本更新,从而保证数据锚和链下数据之间能够始终同步更新。我们必须要找到新的零知识证明技术,来处理大量数据,在很短的时间里就要完成对数据的处理。同时,也要保证数据同步性,也就是说链下数据几乎是每分钟、每一天都要更新,链上也应该做到同步。
当前,安比实验室最近正在着手解决的问题是如何为链下大量数据生成证明,比如说当提高大量数据的时候,需要具有丰富结构的数据,比如说多张数据表,而且这些数据表彼此是有联系的。所以,我们必须要使用统计学、query 查询函数来处理这些数据,将这些数据放在一起,可能涉及到数学的运算。比如说加减乘除,同时也要把它做成列表,或者是其他的。
去年发现了新的 ZK 证明生成方法,专门处理大块数据。我说的大块数据就是几 GB 的数据,新的 ZK 证明方法专门用于处理并行数据。而且数据的处理也可以分层,这就是在数据处理方面的通用型模型。比如说像 MapReduce 这样的模型,我认为大多数数据处理都可以分类成 MapReduce 模型,或者说 MapReduce 之后再进一步变成 MapReduce。去年我们也做了一个 demo,可以快速查询具有数百万条数据记录的数据表,生成证明的速度非常快。同样,也可以用深度神经网络实现数据的处理,比如说可以在短短几小时之内为 VGG16 卷积神经网络的面部识别生成证明。
ZK 证明电路可以有几十亿乘法门,当前我们正在做的就是持续不断优化整个框架。也引入了很多新的加密工具,主要是以太坊基金会研发出来的,从而改变最底层的。换句话说,用新的加密承诺来取代旧的加密承诺,而且在这方面实现了不断的优化,大量的提升。
总结来说,可以使用新的零知识证明工具,可以借助一些智能合约,轻松地证明历史数据。比如说以太坊的区块数据,证明在以太坊上一些历史的记录,证明人的身份,他们的资产,他们的资产持有情况等等。
总结来说,未来将会和现在大不相同,我们会有一些新的技术、新的方案、新的协议,从社区开发而来。我觉得未来令人兴奋。
Blue(主持人):感谢郭宇,这就是今天圆桌论坛要讨论的所有问题,感谢所有圆桌嘉宾。
主持人:感谢几位嘉宾精彩的讨论和分享,谢谢。
今天,我们从各位嘉宾的分享中,了解到了多个区块链隐私安全和数据治理的解决方案,积土成山,只有打牢了安全的「地基」,才能筑起结实的未来。再次感谢各位嘉宾带来的精彩观点,谢谢。
各位观众,第八届区块链全球峰会——积「土」成山主题论坛的日程到这就结束了,感谢各位的聆听和陪伴。
明天 14:00,我们将在我们的母星——地球,邀请多位行业专家,一起探讨物联网等数字化技术如何赋能碳中和,助力打造绿色可持续的生存家园。
也再次提醒大家,观看第八届区块链全球峰会,参与互动活动,将有机会获得主办方万向区块链实验室准备的大疆无人机、米家投影仪、Switch 健身套装、峰会定制限量版 NFT 等丰厚礼品。点击直播间下方的「直播福利」,即可查看获取奖品的详细规则。
请大家持续关注第八届区块链全球峰会,期待明天 14:00,再次与大家相会在直播间里。谢谢!
{kind=link}